15. Convolutional Neural Network#
CNN, 畳み込みニューラルネットワーク [貴之, 2016]

CNNのイメージ 出典:畳み込みニューラルネットワーク(CNN) – ニューラルネットワーク・DeepLearningなどの画像素材 プレゼン・ゼミなどに【WTFPL】
Show code cell source
# packageのimport
from typing import Any, Union, Callable, Type, TypeVar
from tqdm.std import trange,tqdm
import numpy as np
import numpy.typing as npt
import pandas as pd
import matplotlib.pyplot as plt
import plotly.express as px
import seaborn as sns
from PIL import Image
import cv2
import requests
# pytorch関連のimport
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
SEED = 2023_6_27
from src import utils
utils.set_seed(SEED)
15.1. CNNとは#
15.1.1. CNNの歴史#
動物の視覚屋の神経細胞の二つの動き:
画像の濃淡パターンを検出する機能
物体の位置ズレを許容して同一物体だとみなす機能
を再現したモデルがCNNです.これを組み込んだ最初期のモデルはネオコグニトロン(Negcognitron)と呼ばれ,福島邦彦氏によって発表されました[Fukushima, 1980].訓練は自己組織化によって行われます.
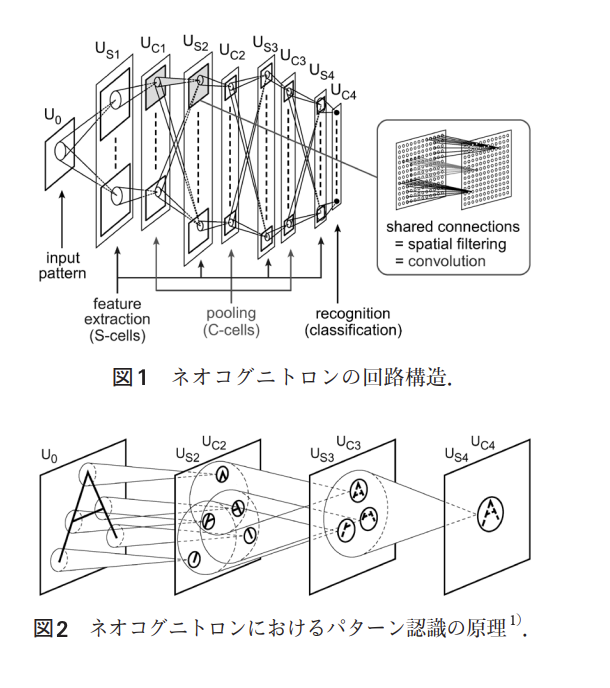
現在主流のCNNはネオコグニトロンをベースに,訓練方法を誤差逆伝播法に変えられています.そしてその後にCNNは更に深層化し,様々な画像認識タスクで当時のSoTA(State-of-the-Art, 現時点での最先端レベルの性能)を叩き出しました.特に有名なのが2012年のILSVRC(ImageNet Large Scale Visual Recognition Challenge)という画像認識コンペティションでしょう.ここでGeoffrey Everest HintonらのチームがAlexNetというCNNで,これまでの誤差率を10%以上を改善し,大成功を収めたのが有名です.[Krizhevsky, Sutskever, and Hinton, 2012]
15.1.2. 初期のCNNの有名なモデル#
15.1.2.1. LeNet#
基本的なCNNアーキテクチャのモデルです.
関係する論文:
15.1.2.2. AlexNet#
前述した通り,2012年のILSVRC(ImageNet Large Scale Visual Recognition Challenge)で優勝したモデル[Krizhevsky, Sutskever, and Hinton, 2012].
これまでの誤差率を10%以上を改善し,Deep Learningブームを引き起こしました.
また,ImageNetという大規模画像データセット[Deng, Dong, Socher, Li, Li, and Fei-Fei, 2009]自体の登場も,CNNの発展に大きく寄与しました.
15.1.2.3. VGG#
2014年のILSVRCにおけるImageNetを用いた画像認識精度のコンペティションで画像分類部門で2位、物体のローカライゼーション部門で1位を記録したモデルです.[Simonyan and Zisserman, 2014]
当時では大きな数である(Conv, MaxPool, Linearを合計して)16層のモデルです.
15.1.2.4. GoogLeNet#
InceptionNetと名付けられたモデルの中の最初のバージョン,Inception v1はGoogLeNetとも呼ばれています.[Szegedy, Liu, Jia, Sermanet, Reed, Anguelov, Erhan, Vanhoucke, and Rabinovich, 2015]
複数の畳み込み層やpooling層から構成されるInceptionモジュールと呼ばれる小さなネットワーク (micro networks) を定義し,これを通常の畳み込み層のように重ねていくことで1つの大きなCNNを作り上げている点である.
引用:畳み込みニューラルネットワークの最新研究動向 (〜2017)
15.2. 画像データ#
15.2.1. 画像データの配列#
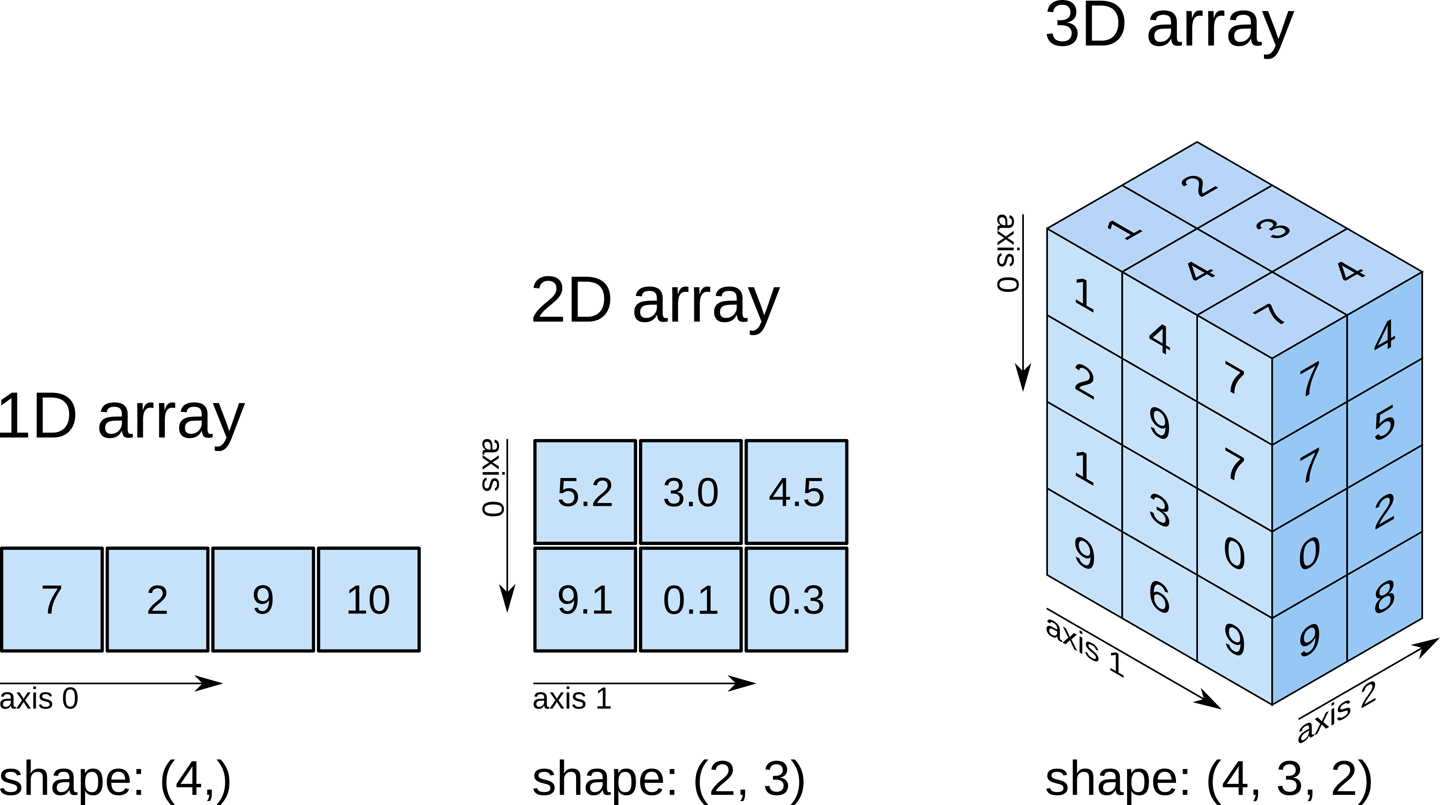
iris datasetは一つのデータが一次元配列で表現されていました.これに対してこれから扱う画像データは:
各ピクセルがグレースケールの色情報を持っている時,一つのデータは2次元配列として表現されます.
各ピクセルがRGBの色情報を持っている時,一つのデータは3次元配列として表現されます.
Show code cell source
path = "./figs/cnn/stablediffusion_dog_grayscale.jpeg"
img = cv2.imread(path)
plt.imshow(img)
plt.show()
# 画像はgrayスケールで作成したはずですが,実際には3色持っているので配列を見せる時は変換しています.
print("このようなグレースケールの画像ならば,二次元配列で表現することができます:")
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
print(gray_img.shape)
print(gray_img)
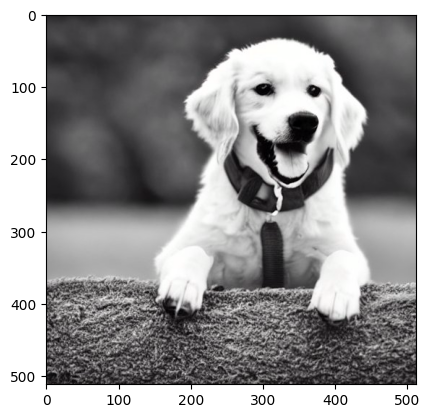
このようなグレースケールの画像ならば,二次元配列で表現することができます:
(512, 512)
[[40 40 40 ... 67 67 67]
[42 42 41 ... 67 67 67]
[44 44 43 ... 68 68 68]
...
[74 80 75 ... 37 46 44]
[62 74 74 ... 37 46 52]
[58 67 74 ... 51 53 59]]
Show code cell source
path = "./figs/cnn/stablediffusion_dog.jpeg"
img = cv2.imread(path, cv2.COLOR_RGB2BGR)
plt.imshow(img)
plt.show()
print("このようなカラー画像だとRGBの3チャネルが必要なので,三次元配列になります:")
print(img.shape)
print(img[:2,:,:])
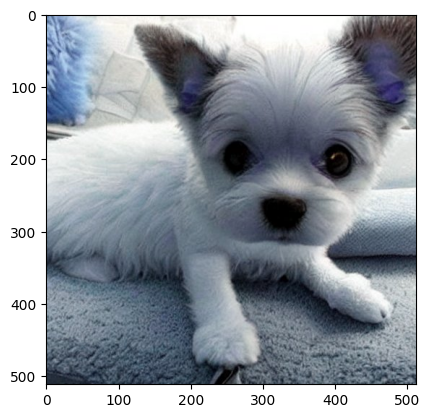
このようなカラー画像だとRGBの3チャネルが必要なので,三次元配列になります:
(512, 512, 3)
[[[118 146 181]
[129 157 192]
[129 156 193]
...
[102 94 87]
[108 100 93]
[104 96 89]]
[[113 141 176]
[124 152 187]
[126 153 190]
...
[ 99 91 84]
[100 92 85]
[ 97 89 82]]]
15.3. CNNのアーキテクチャ#
15.3.1. 画像データのためのニューラルネットワーク#
さて,MLPでは二次元配列の位置情報をうまく扱うことができませんので,仮にMLPにgrayスケールの画像を入力したいならば,一つのデータが一次元配列で表現されるようにshapeを変える必要があります.
print("オリジナル:", gray_img.shape)
print("変換後:", gray_img.flatten().shape)
オリジナル: (512, 512)
変換後: (262144,)
しかし画像ですからこの二次元配列は位置情報自体が意味を持っています.これでは画像データをうまく扱うことはできないでしょう.そこでCNNの登場です.
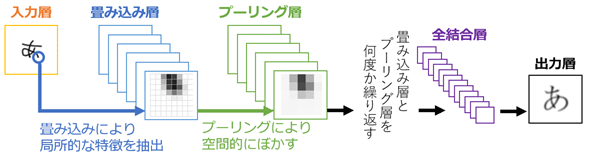
15.3.2. 畳み込み#
畳み込み(convolution)は画像データから特徴を抽出するためによく用いられる操作です.
あるカーネルに着目して,入力画像が1チャネルの場合の計算の様子を見てみましょう.
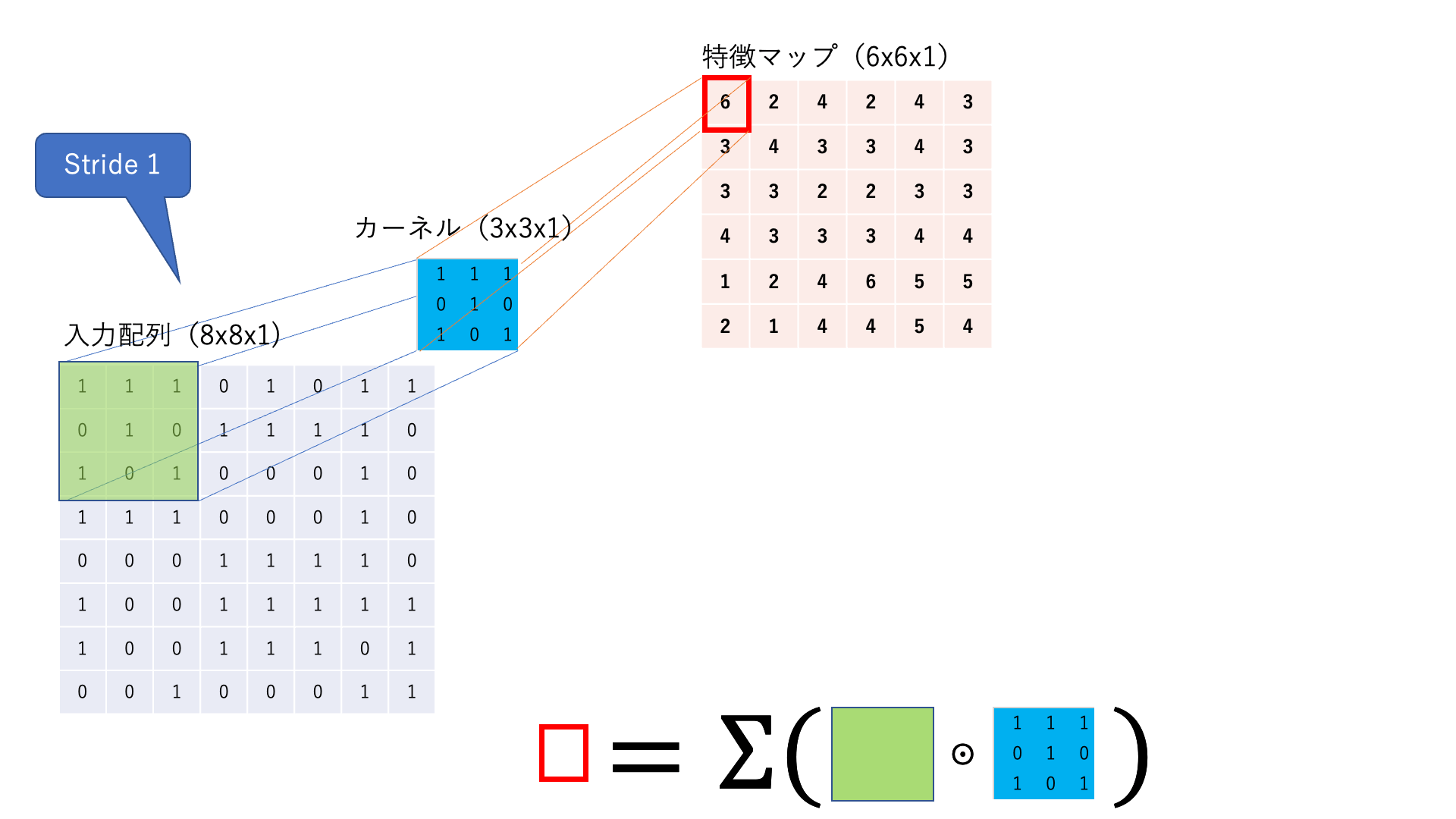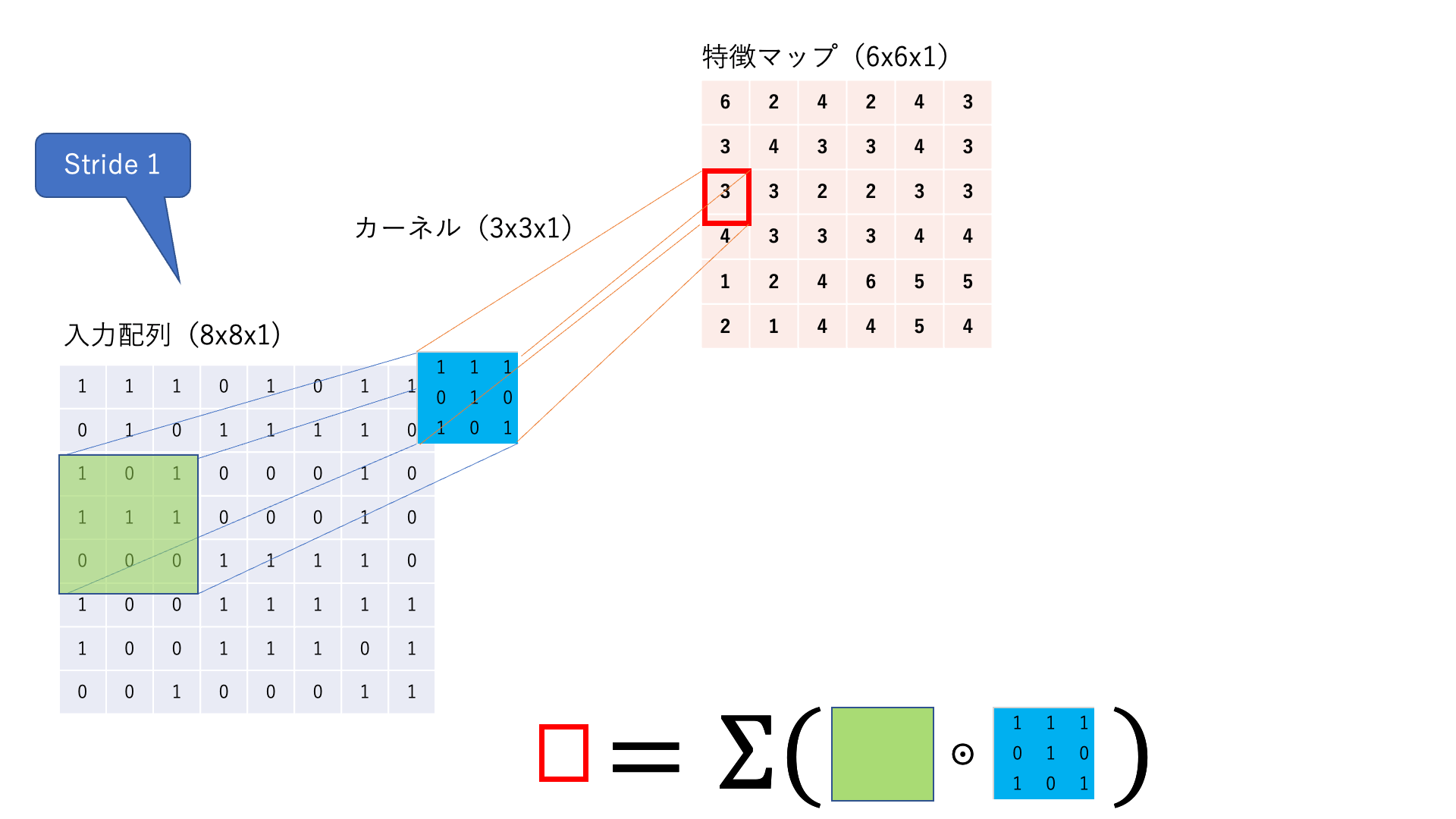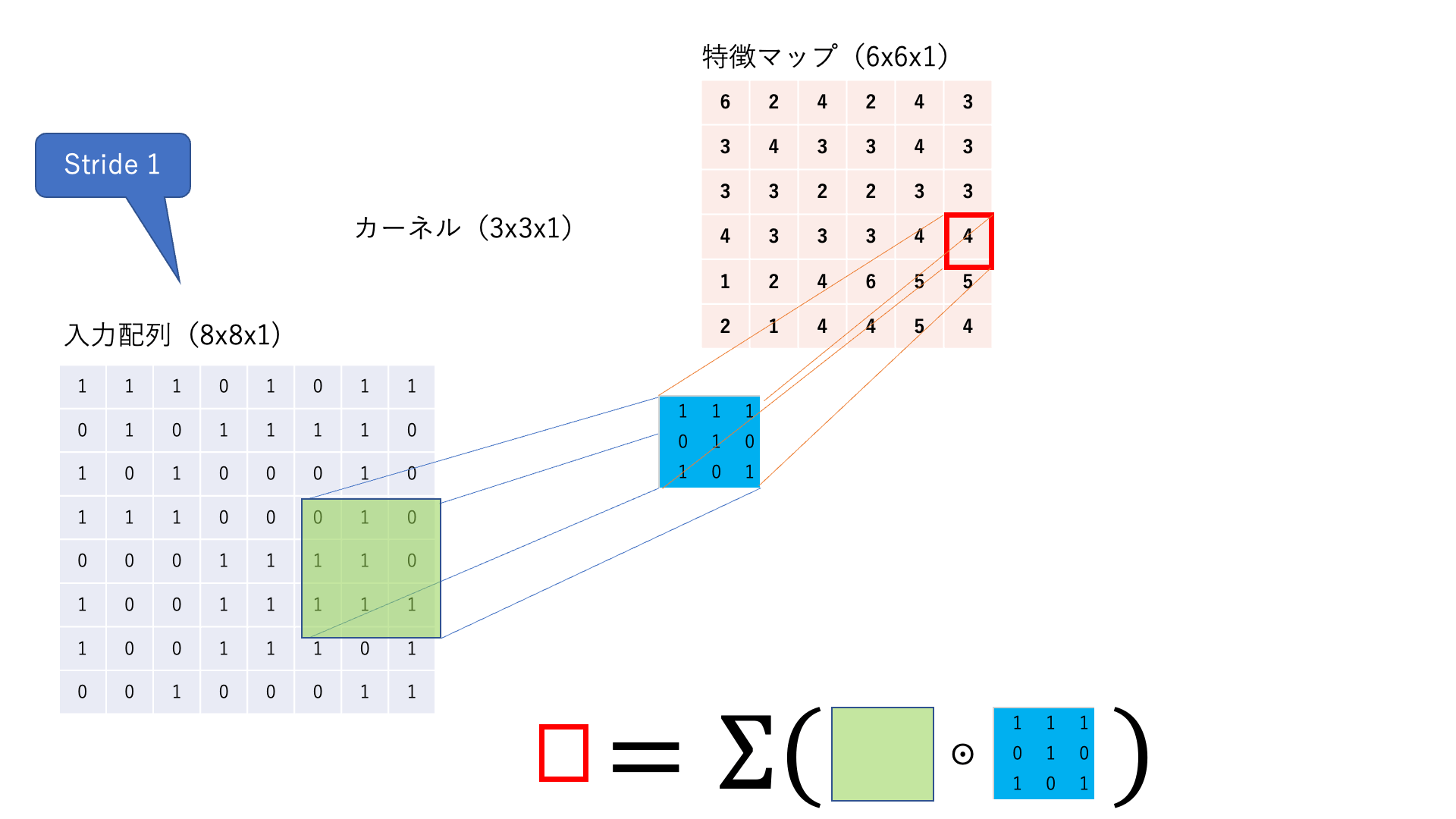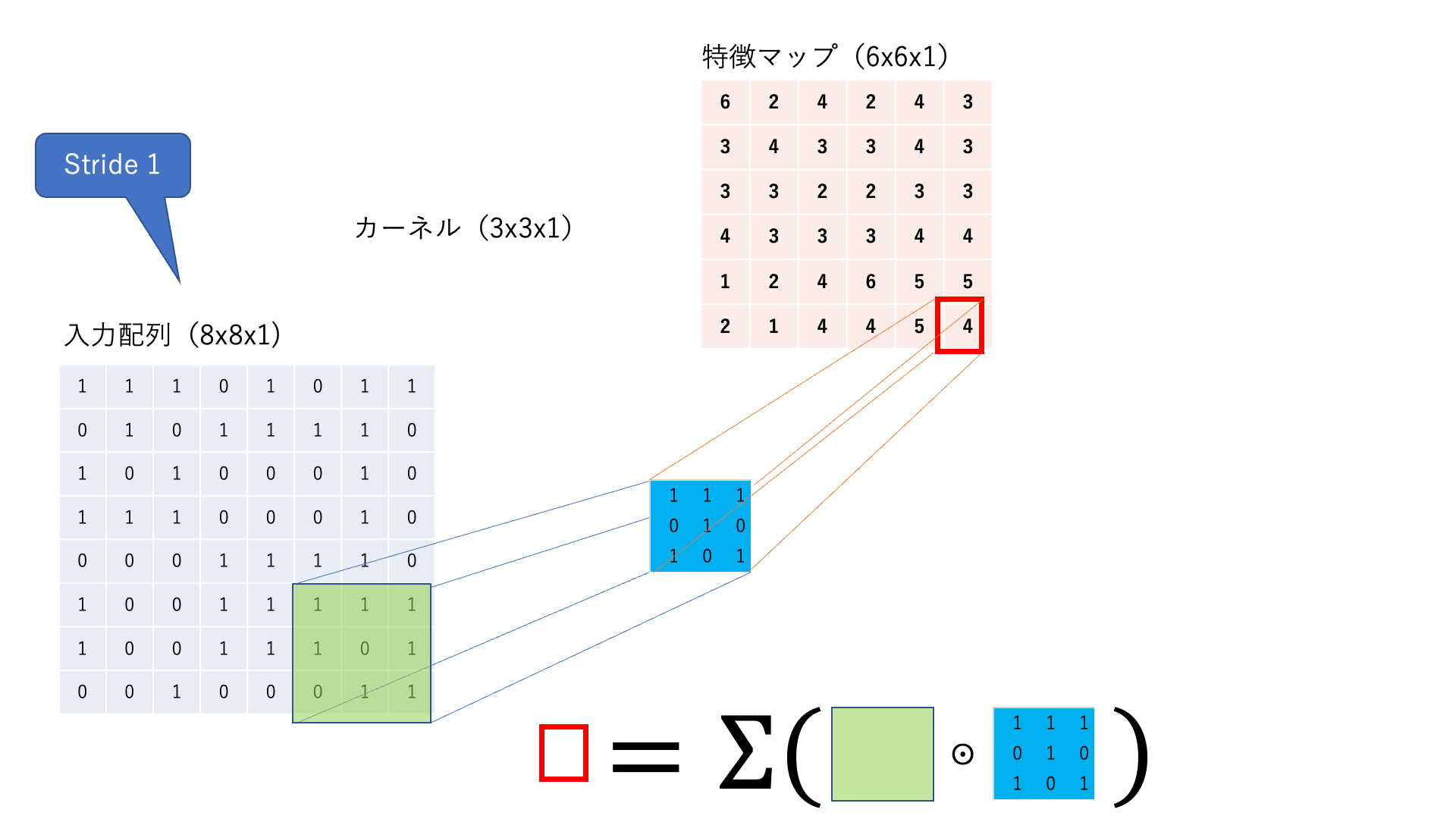
図:畳み込み処理の仕組み(簡単のためにバイアスを描いていませんが,使われる場合もあります.)
フィルタ と呼ばれる行列を使って,画像の特徴を抽出する作業を 畳み込み と呼びます.画像左上から,フィルタとそれに対応するピクセルを掛け合わせて,総和をとります.この操作を画像の右下まで続けて新しい二次元配列を得ます.
これを 特徴マップ と呼びます.
尚,ウィンドウを動かす幅を ストライド(stride) と呼びます.上の図ではStrideが1,カーネルサイズが3x3です.
数式にして少し整理してみましょう.特徴マップのある要素を\(a_{i,j}^{(k)}\)と書くことにします.これを求める手順をおさらいします.
高さ\(H\), 幅\(W\)とします.インプットデータが1チャネルだとすると:
また,カーネルサイズを\(m \times n\)として,\(K\)個のカーネルのカーネル\(k\)に着目すると:
最後に,biasは\(K\)個あるので:
畳み込み層では行列の左上から右下にカーネルを走査させていきますが,\(x_{i,j}\)に着目すると,その時点の畳み込み処理の結果\(a_{i,j}^{(k)}\)は以下のように求まります.
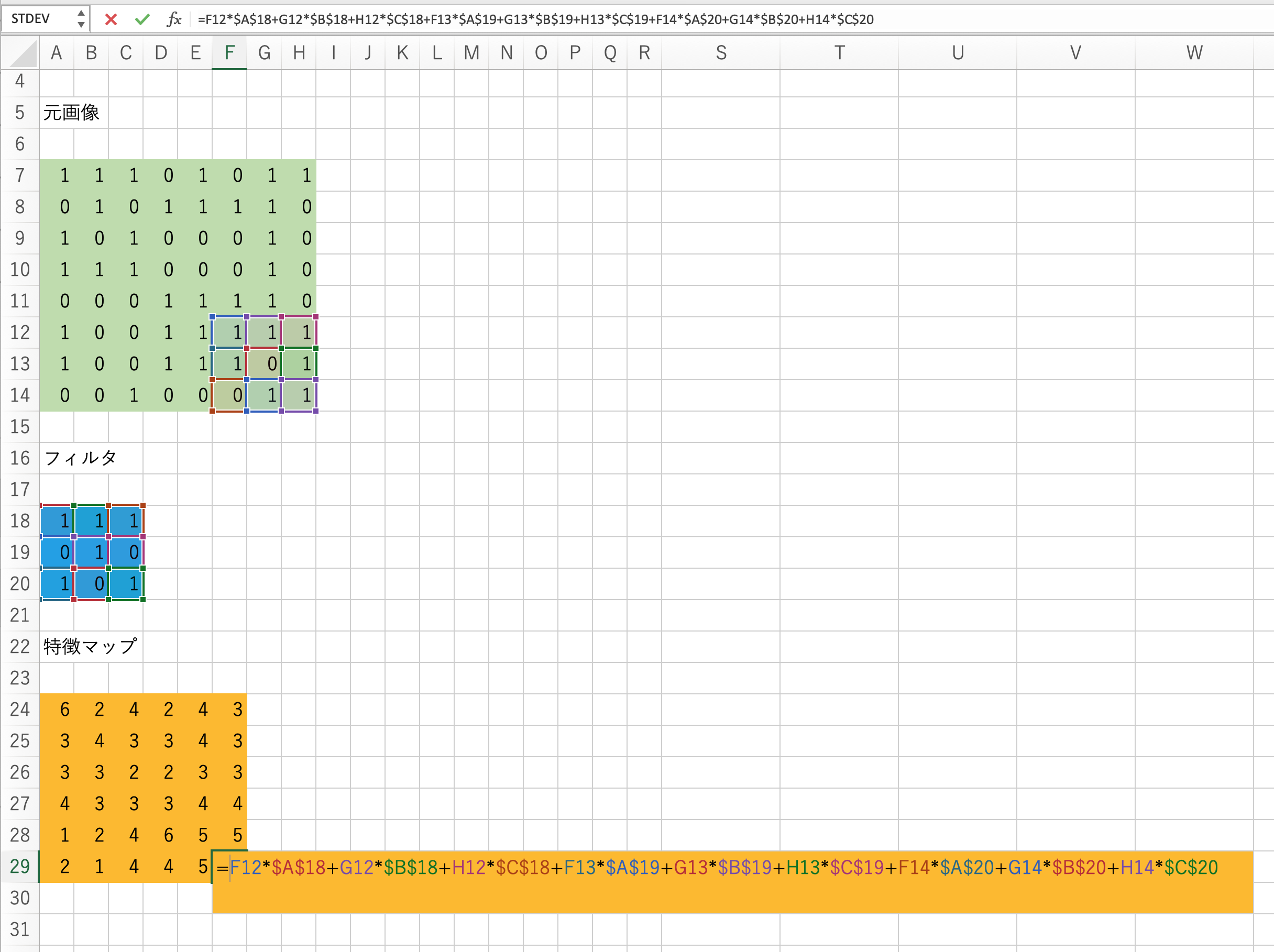
畳み込み層をエクセルで実装すると以下のようになります.
また,普通は入力画像がRGBの3チャネルであることが多いので,その場合の畳み込み演算の様子も見ておきましょう.
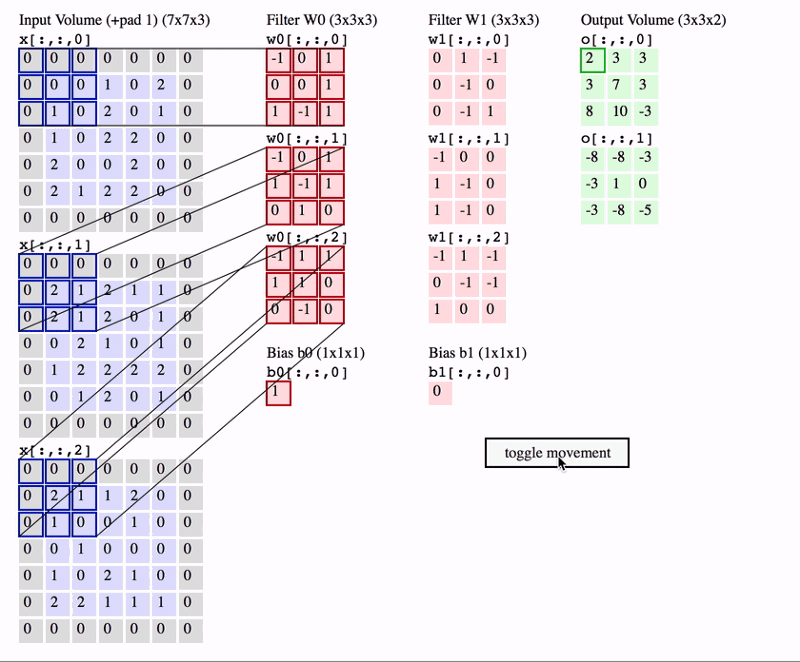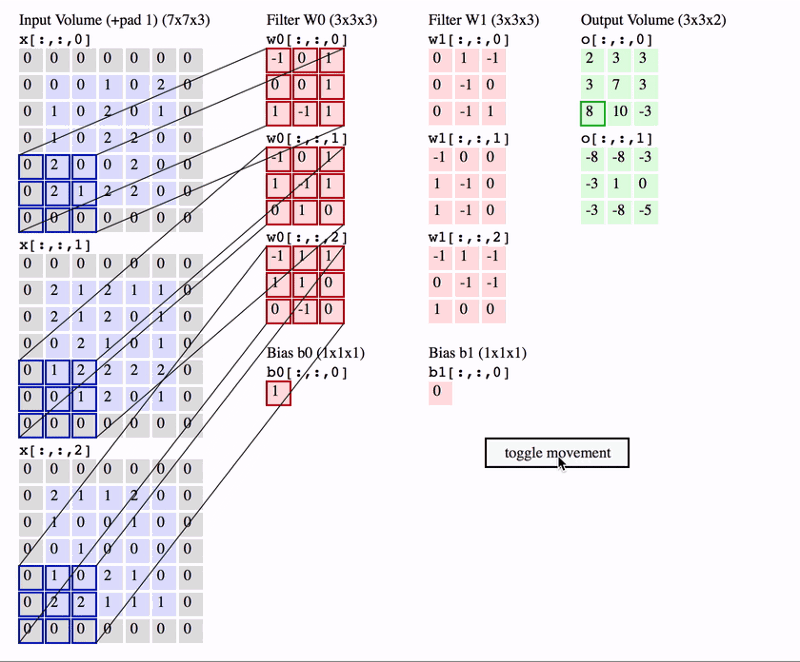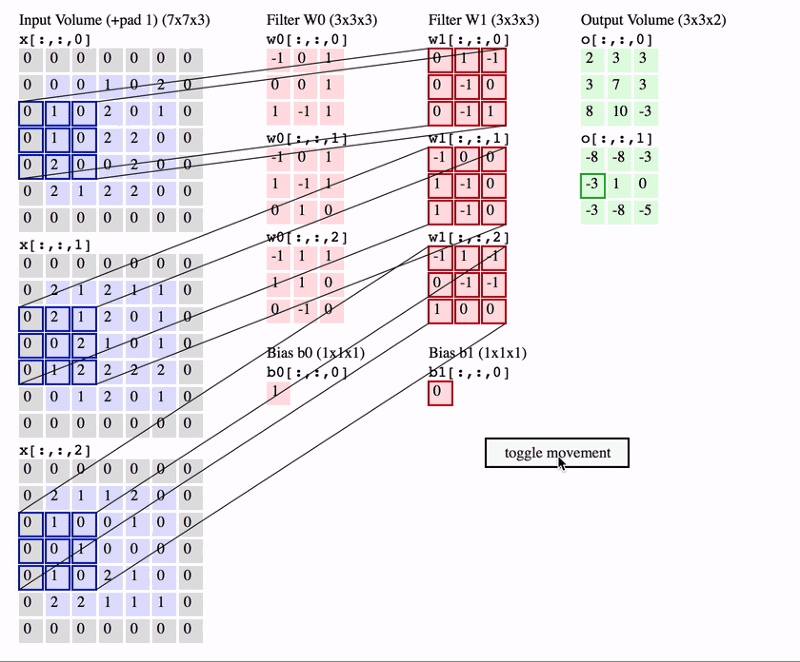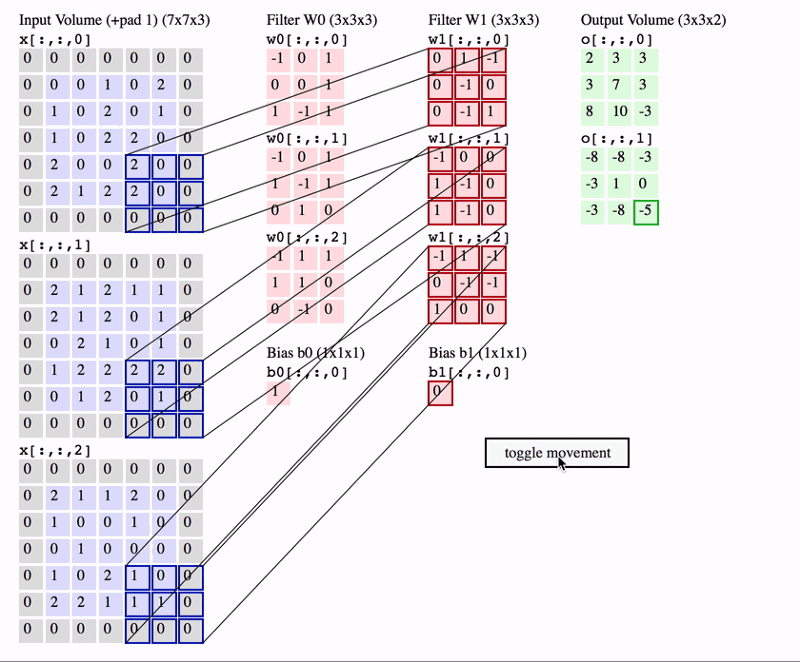
出典:Everything you need to know about Convolutional Neural Networks (CNNs)
一つのカーネルは\(\text{縦} \times \text{横} \times \text{チャネル}\)の配列を持っていることになり,これを任意の個数だけ用意することで畳み込み層が実装できます.
15.3.3. パディング#
画像によっては,端にあるピクセルに重要な特徴があることが考えられます.そんな時,画像の周りに適当な数字を敷き詰めることで画像を大きくする(枠をつける)ことで対応します.これを パディング(padding) と呼びます.

15.3.4. プーリング#
プーリング は,任意のサイズ(例えば2x2)ごとに対象の範囲を何かしらの代表値に置き換える処理です.処理の流れはカーネルサイズとストライドサイズが同じ畳み込みのように見えます.基本的にここでのスライディングウィンドウは前後で被りがないので,特徴マップはチャネル数は変わらないままでサイズ(縦と横)だけが小さくなります.
Max Pooling:
特徴マップに対してスライディングウィンドウ処理を行い,各カーネルごとにその範囲を最大値に置き換えてダウンサンプリングします.
Average Pooling:
特徴マップに対してスライディングウィンドウ処理を行い,各カーネルごとにその範囲を平均値に置き換えてダウンサンプリングします.
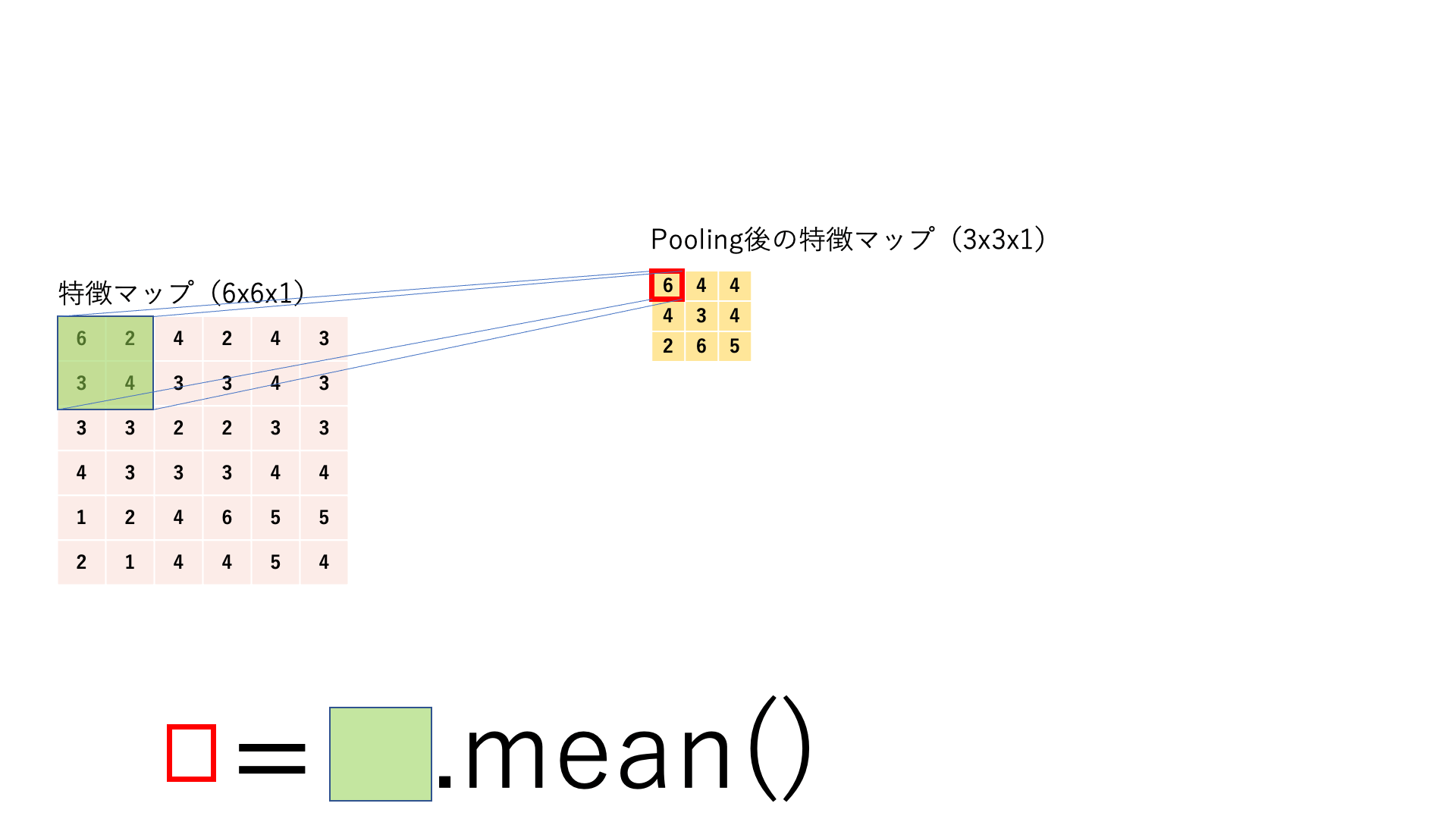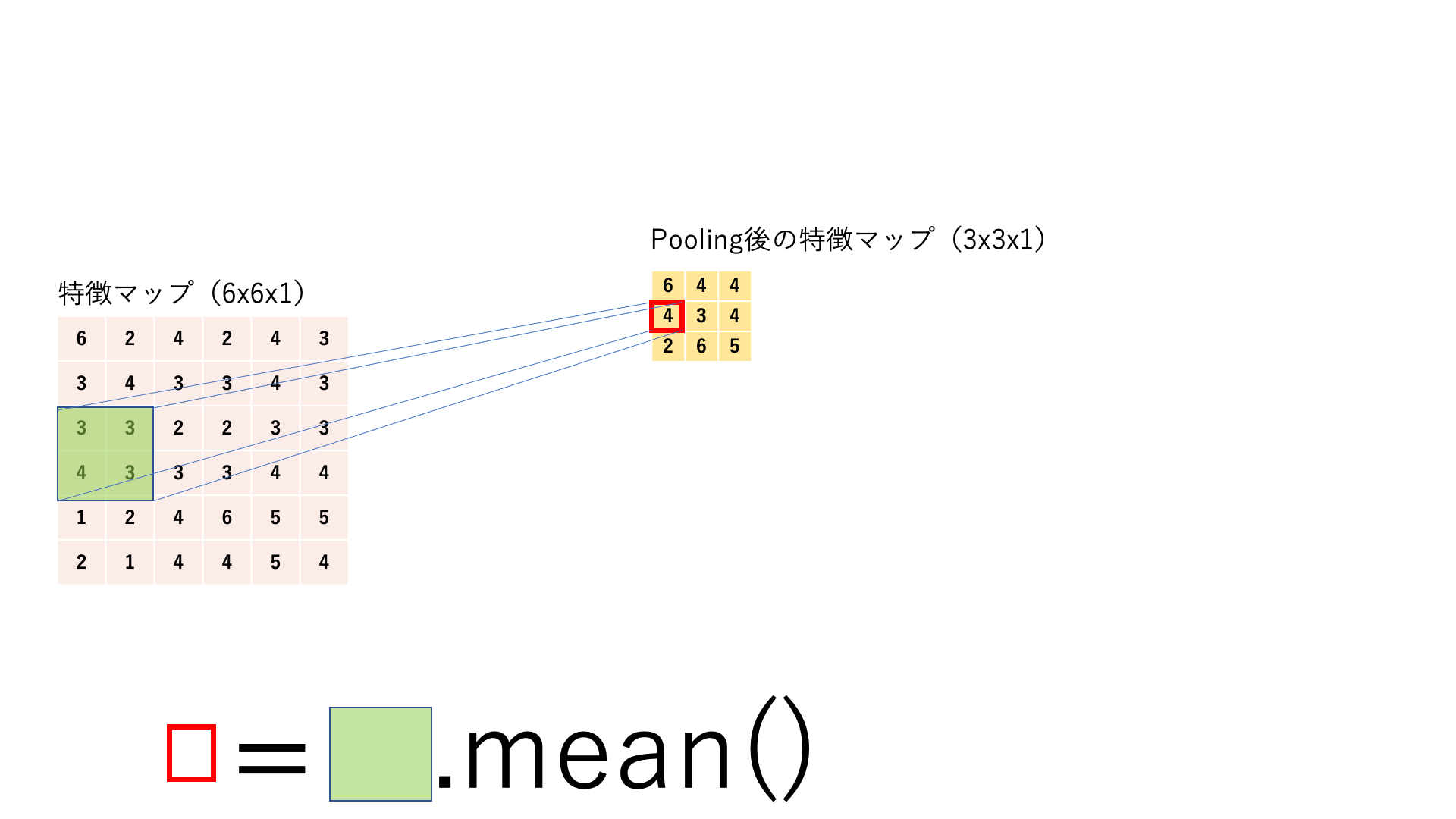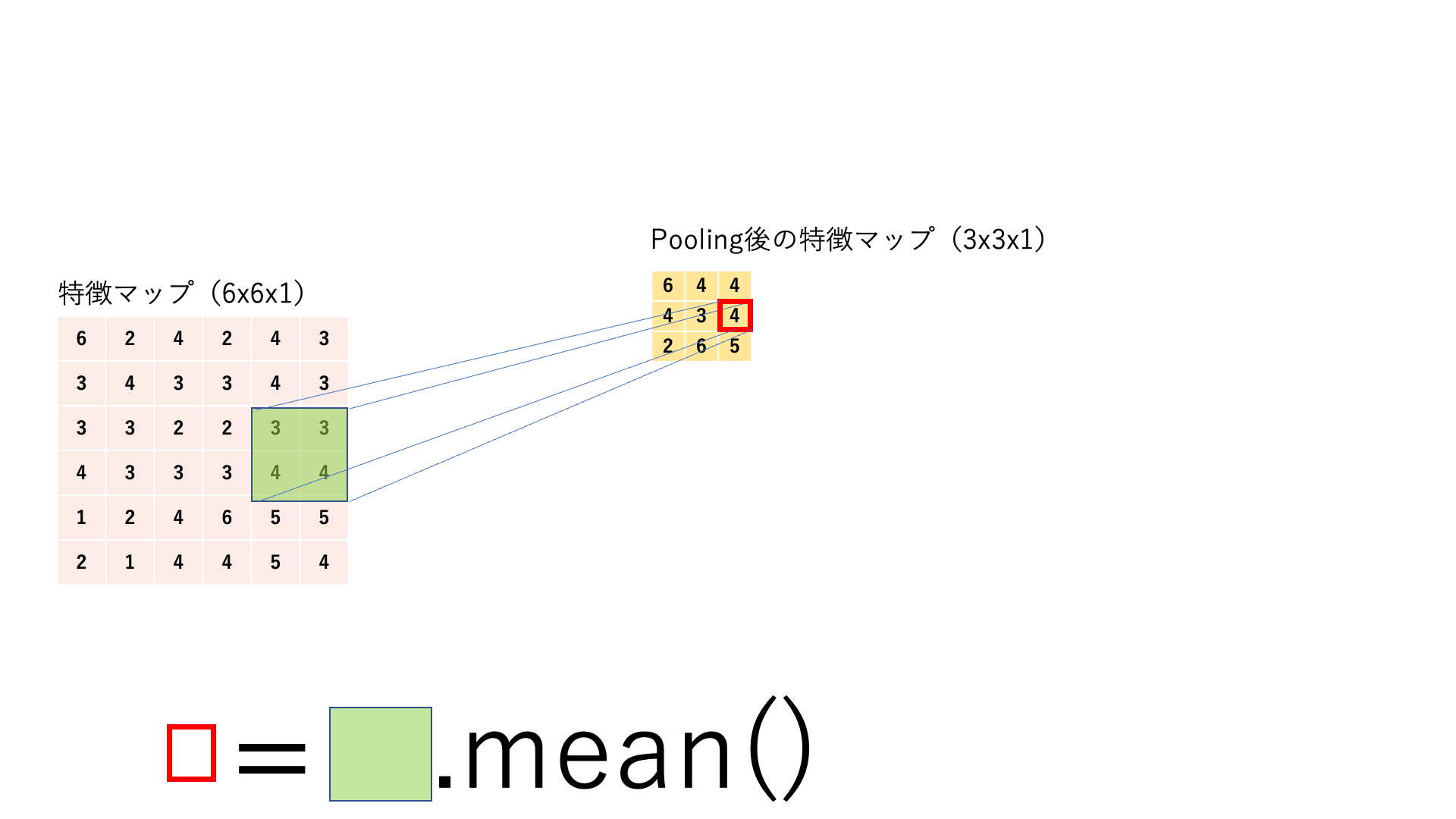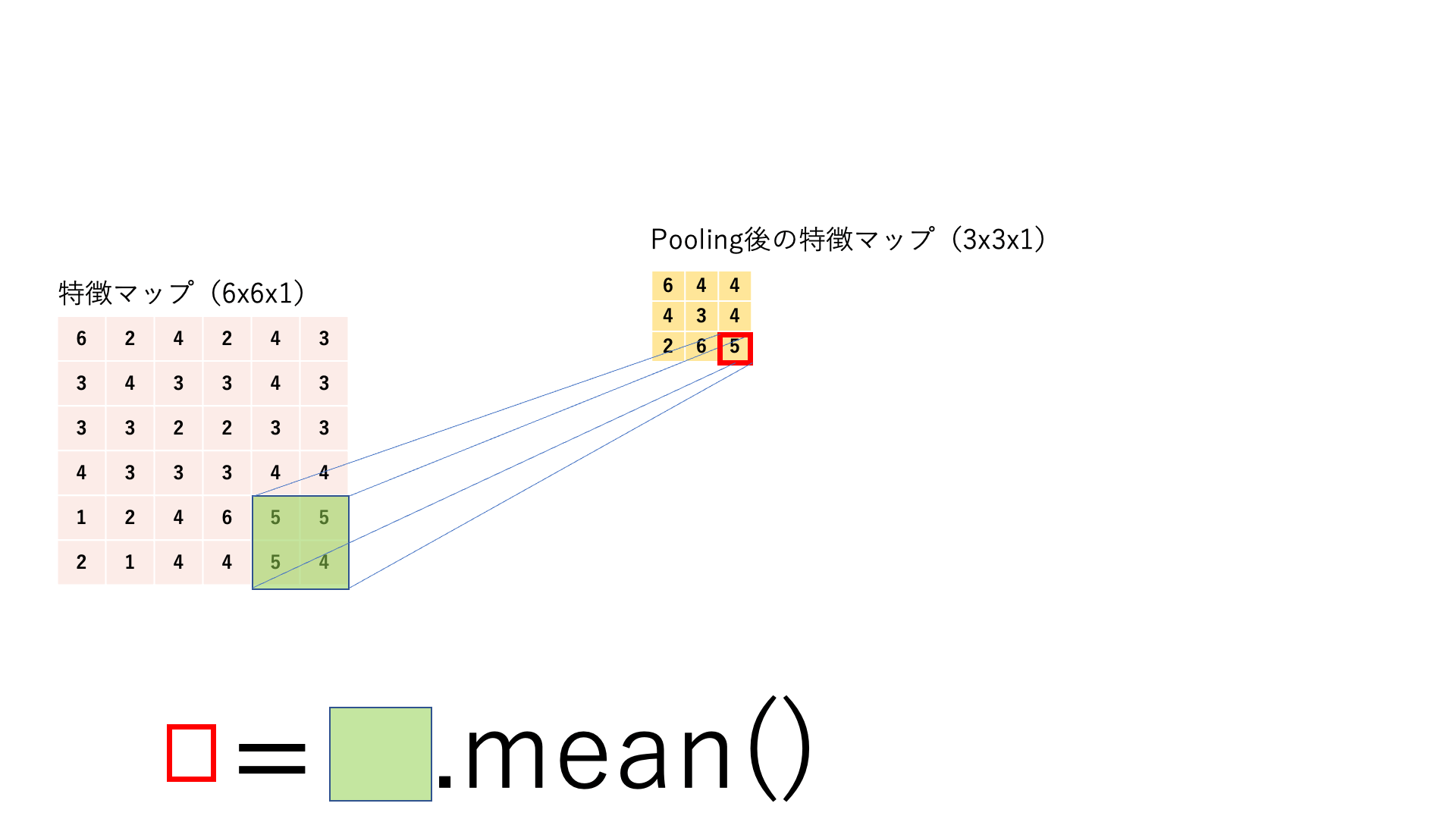
図:Pooling処理の仕組み
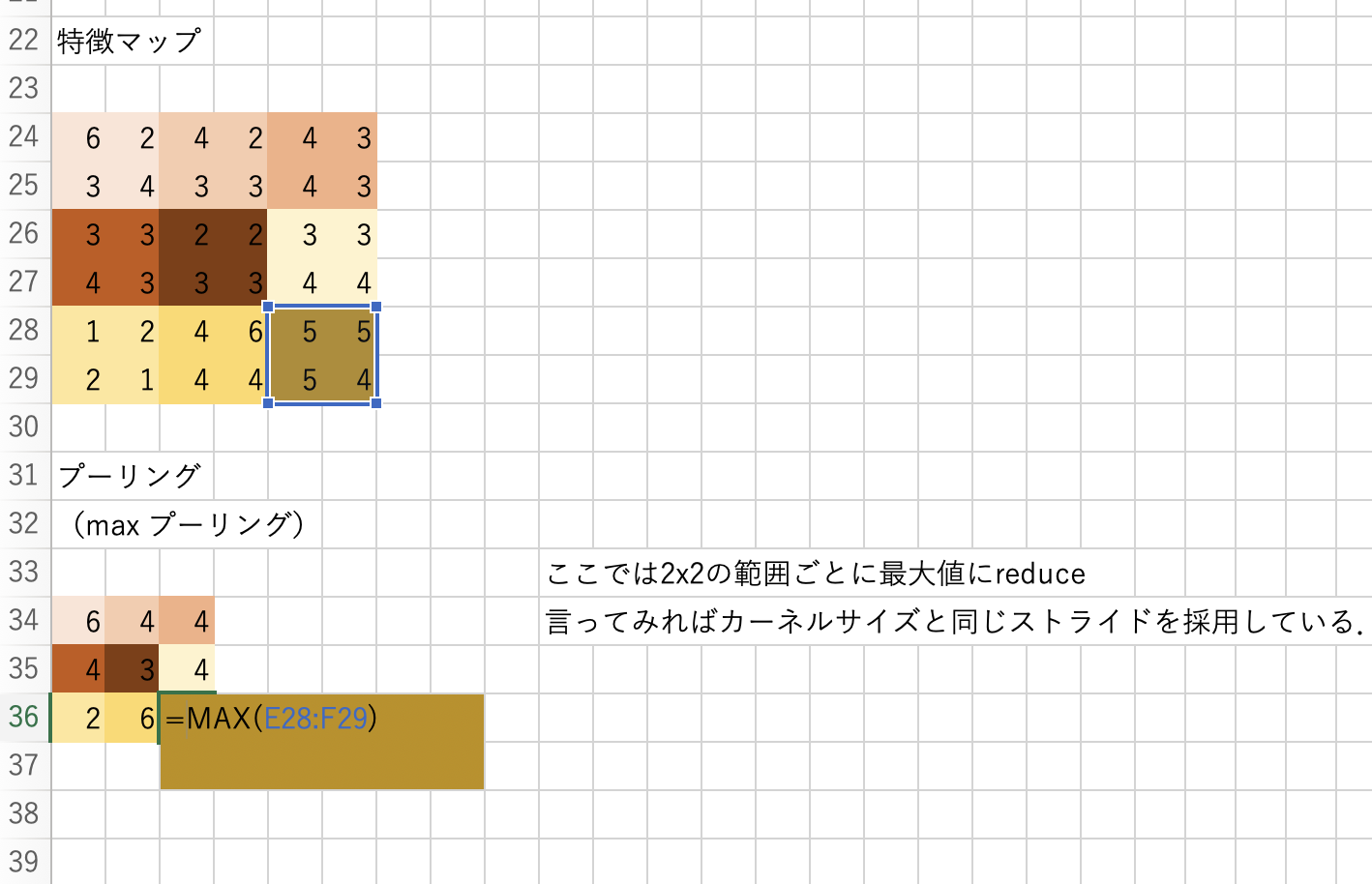
15.4. CNNの実装#
15.4.1. 作成するアプリケーションのイメージ#
ここでは0~9の数字の手描き文字認識アプリをCNNで実装します.言い換えると,手書きの数字の画像データを受け取って,それを0~9のクラスに分類するタスクです. Hugging Face Spaces (機械学習のデモアプリが投稿されるサービス)にちょうど良いアプリが公開されていたので,実装例を確認しておきましょう.
左枠に手書きで0~9のうち,どれかの数字を書いてみてください.右枠に認識結果が表示されます.
ここではWeb UIから実際に手書きで文字を書けるようになっていますが,今回はそこまでは行わずにベンチマークデータセットから画像データを取ってきて訓練とテストを行います.
15.4.2. データの準備#
今回はMNISTという手書き文字データセットを利用します.これはCVの世界でのirisのような有名なデータセットなので,pytorchに収録されています.
ここで,データは[Batch size,Channel,Height,Width]という順番になっている事に注意してください.Channelは色の数です.ここではグレースケールなので1です.
def load_MNIST(batch=128):
transform = transforms.Compose([
transforms.ToTensor(),
#transforms.Normalize((0.1307,), (0.3081,)),
])
train_set = torchvision.datasets.MNIST(root="./data",
train=True,
download=True,
transform=transform)
train_loader = torch.utils.data.DataLoader(train_set,
batch_size=batch,
shuffle=True,
num_workers=2)
val_set = torchvision.datasets.MNIST(root="./data",
train=False,
download=True,
transform=transform)
val_loader =torch.utils.data.DataLoader(val_set,
batch_size=batch,
shuffle=True,
num_workers=2)
return {"train":train_loader, "validation":val_loader,"train_dataset": train_set, "val_dataset":val_set}
訓練データセットの最初の一枚を取り出して表示してみましょう.28x28の画像で,中身は手書きの数字になっています.
data_loader = load_MNIST(batch=1)
train_loader= data_loader["train"]
img,label = next(iter(train_loader))
print("img:",type(img), img.size(), img.dtype)
print("label:", type(label), label.size(), label.dtype)
print("\t",label, )
plt.imshow(img.view(-1,28), cmap='gray')
img: <class 'torch.Tensor'> torch.Size([1, 1, 28, 28]) torch.float32
label: <class 'torch.Tensor'> torch.Size([1]) torch.int64
tensor([5])
<matplotlib.image.AxesImage at 0x1552cea70>
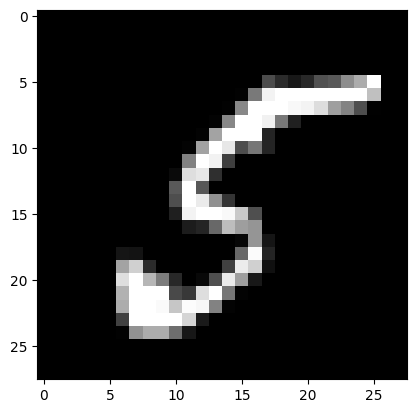
0~9の数字があるので,全部で10クラスの分類を行います.
15.4.3. CNNクラス#
PyTorchを使って実装するならば,これまで考えてきた難しいアーキテクチャのことは一度忘れて,ブロックを重ねるようにネットワークを作ることができます.ただし,MLPとは異なり,レイヤーを通った後のテンソルの形状がわかりにくいことに注意してください.
例えば,畳み込み→プーリング→畳み込み→プーリング→MLP のようなネットワークの場合,入力されたテンソルには以下のような形状の変化が起こります.
x = torch.from_numpy(np.random.random([64,1,28,28]).astype(np.float32))
print(x.shape)
y = nn.Conv2d(1,32 ,3,1)(x) # 第一引数(入力チャネル数)を決め打ちしておかないといけない
print(y.shape)
y = nn.MaxPool2d(2,2)(y)
print(y.shape)
y = nn.Conv2d(32,64, 3,1)(y)
print(y.shape)
y = nn.MaxPool2d(2,2)(y)
print(y.shape)
y = nn.Flatten()(y)
print(y.shape)
y = nn.Linear(1600,10) # 第一引数を決めうちしておかないといけない.
torch.Size([64, 1, 28, 28])
torch.Size([64, 32, 26, 26])
torch.Size([64, 32, 13, 13])
torch.Size([64, 64, 11, 11])
torch.Size([64, 64, 5, 5])
torch.Size([64, 1600])
入力画像を最初に適用するnn.Conv2dの第一引数と,畳み込みやプーリングを繰り返した後にnn.Flattenした際の特徴数の計算が難しそうです. 以下のような関数でConv層の出力する画像の縦横サイズを求められるので,使ってみてください.
def get_output_shape(
height:int,
padding:int,
kernel_size:int,
stride:int,
)->int:
new_height = (height+2*padding-kernel_size)/stride + 1
return int(np.floor(new_height))
h = get_output_shape(28,0,3,1)
print(h)
h = get_output_shape(h, 0, 2,2)
print(h)
h = get_output_shape(h,0,3,1)
print(h)
h = get_output_shape(h,0,2,2)
print(h)
26
13
11
5
では,単純なCNNをnn.Sequentialで作成します.
def build_cnn(in_channels:int=1, n_classes:int=10):
"""
28*28の画像だけ受け付ける
"""
return nn.Sequential(
nn.Conv2d(in_channels, # 入力されるチャネル数
32, # 出力したいチャネル数
3, # カーネルサイズ
1, # ストライド
0, # パディング
),
nn.ReLU(),
nn.MaxPool2d(2, # カーネルサイズ
2, # ストライド
),
nn.Conv2d(32,64, 3, 1, 0),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Dropout2d(0.25),
nn.Flatten(),
nn.Linear(64*5*5,128),
nn.ReLU(),
nn.Linear(128,n_classes)
)
cnn = build_cnn(3)
x = torch.from_numpy(np.random.random([64,3,28,28]).astype(np.float32))
cnn(x).shape
torch.Size([64, 10])
また,テンソルの形状を考えるのが面倒な場合は,以下のようなLazyHogehoge(nn.LazyConv2d, nn.LazyLinearなど)を使うことで入力チャネルや入力特徴数の計算を省けます.
def build_lazy_cnn(n_classes:int=10):
"""
28*28の画像だけ受け付ける
"""
return nn.Sequential(
nn.LazyConv2d(#in_channels, # 入力されるチャネル数
32, # 出力したいチャネル数
3, # カーネルサイズ
1, # ストライド
0, # パディング
),
nn.ReLU(),
nn.MaxPool2d(2, # カーネルサイズ
2, # ストライド
),
nn.Conv2d(32,64, 3, 1, 0),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Dropout2d(0.25),
nn.Flatten(),
nn.LazyLinear(128),
nn.ReLU(),
nn.Linear(128,n_classes)
)
# 例1
_cnn = build_lazy_cnn(10)
x = torch.from_numpy(np.random.random([64,4,15,15]).astype(np.float32))
print(x.shape, "->", _cnn(x).shape)
# 例2
_cnn = build_lazy_cnn(10)
x = torch.from_numpy(np.random.random([64,3,53,53]).astype(np.float32))
print(x.shape, "->", _cnn(x).shape)
torch.Size([64, 4, 15, 15]) -> torch.Size([64, 10])
torch.Size([64, 3, 53, 53]) -> torch.Size([64, 10])
/Users/mriki/.pyenv/versions/miniforge3-4.10.3-10/envs/datasci/lib/python3.10/site-packages/torch/nn/modules/lazy.py:180: UserWarning: Lazy modules are a new feature under heavy development so changes to the API or functionality can happen at any moment.
warnings.warn('Lazy modules are a new feature under heavy development '
15.4.4. 学習スクリプト#
ここまで来ればMLPと同じような学習スクリプトで訓練することができます.
## ハイパーパラメータなどの設定
#エポック数,バッジサイズ
max_epochs = 20
batch_size = 64
#データのロード
data_loader = load_MNIST(batch=batch_size)
#GPUが使えるときは使う
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
#ネットワーク構造の構築
net = build_cnn(1,10)
print(net)
cpu
Sequential(
(0): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Dropout2d(p=0.25, inplace=False)
(7): Flatten(start_dim=1, end_dim=-1)
(8): Linear(in_features=1600, out_features=128, bias=True)
(9): ReLU()
(10): Linear(in_features=128, out_features=10, bias=True)
)
15.4.4.1. skorchを使った簡易版#
以下のコードはこちらを参考にしました.
import skorch
from skorch import NeuralNetClassifier
trainer = NeuralNetClassifier(
net,
max_epochs=max_epochs,
batch_size=batch_size,
lr=0.01,
criterion=nn.CrossEntropyLoss,
optimizer= torch.optim.Adam,
device=device,
)
train_dataset = data_loader["train_dataset"]
y_train = np.array([y for x, y in iter(train_dataset)])
trainer.fit(train_dataset, y_train)
Show code cell output
epoch train_loss valid_acc valid_loss dur
------- ------------ ----------- ------------ -------
1 0.9455 0.8973 0.3246 15.3669
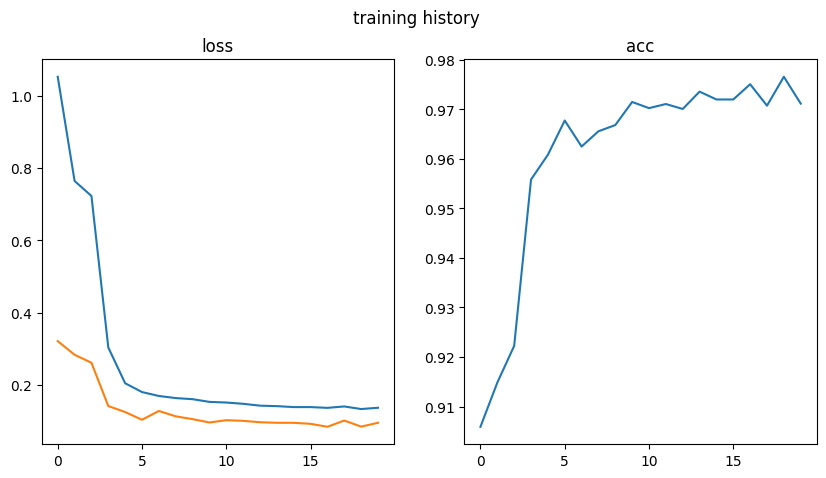
fig = plt.figure(figsize=[10,5])
ax = fig.add_subplot(1,2,1)
ax.set_title("loss")
ax.plot(trainer.history[:,"train_loss"], label="train_loss")
ax.plot(trainer.history[:,"valid_loss"], label="valid_loss")
ax2 = fig.add_subplot(1,2,2)
ax2.set_title("acc")
ax2.plot(trainer.history[:,"valid_acc"], label="valid_acc")
fig.suptitle("training history")
Text(0.5, 0.98, 'training history')
15.4.4.2. フルスクラッチ#
cnn = cnn.to(device)
#学習結果の保存
history = {
"train_loss": [],
"validation_loss": [],
"validation_acc": []
}
#最適化方法の設定
optimizer = torch.optim.Adam(params=net.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
Show code cell output
cpu
Sequential(
(0): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Dropout2d(p=0.25, inplace=False)
(7): Flatten(start_dim=1, end_dim=-1)
(8): Linear(in_features=1600, out_features=128, bias=True)
(9): ReLU()
(10): Linear(in_features=128, out_features=10, bias=True)
)
学習コードです.
for epoch in range(max_epochs):
# training step
loss = None
train_loss = 0.0
net.train()
print("\nTrain start")
for i,(x,y) in enumerate(data_loader["train"]):
x,y = x.to(device),y.to(device)
# 勾配の初期化
optimizer.zero_grad()
# 順伝搬 -> 逆伝搬 -> 最適化
output = net(x)
loss = criterion(output, y)
train_loss += loss.item()
loss.backward()
optimizer.step()
# 途中経過の表示
if (i+1) % 100 == 0:
print("Training: {} epoch. {} iteration. Loss:{}".format(epoch+1,i+1,loss.item()))
train_loss /= len(data_loader["train"])
print("Training loss (ave.): {}".format(train_loss))
history["train_loss"].append(train_loss)
"""validation step"""
print("\nValidation start")
net.eval()
val_loss = 0.0
accuracy = 0.0
with torch.no_grad():
for x,y in data_loader["validation"]:
x,y = x.to(device),y.to(device)
output = net(x)
val_loss = criterion(output,y)
pred_y = output.argmax(dim=1,keepdim=True)
accuracy += pred_y.eq(y.view_as(pred_y)).sum().item()
val_loss /= len(data_loader["validation"])
accuracy /= len(data_loader["validation"].dataset)
print("Validation loss: {}, Accuracy: {}\n".format(val_loss,accuracy))
history["validation_loss"].append(val_loss)
history["validation_acc"].append(accuracy)
Show code cell output
Train start
Training: 1 epoch. 100 iteration. Loss:0.37115180492401123
Training: 1 epoch. 200 iteration. Loss:0.17168577015399933
Training: 1 epoch. 300 iteration. Loss:0.19651196897029877
Training: 1 epoch. 400 iteration. Loss:0.1328047811985016
Training: 1 epoch. 500 iteration. Loss:0.10174187272787094
Training: 1 epoch. 600 iteration. Loss:0.1402805894613266
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[22], line 15
13 loss = criterion(output, y)
14 train_loss += loss.item()
---> 15 loss.backward()
16 optimizer.step()
17 # 途中経過の表示
File ~/.pyenv/versions/miniforge3-4.10.3-10/envs/datasci/lib/python3.10/site-packages/torch/_tensor.py:487, in Tensor.backward(self, gradient, retain_graph, create_graph, inputs)
477 if has_torch_function_unary(self):
478 return handle_torch_function(
479 Tensor.backward,
480 (self,),
(...)
485 inputs=inputs,
486 )
--> 487 torch.autograd.backward(
488 self, gradient, retain_graph, create_graph, inputs=inputs
489 )
File ~/.pyenv/versions/miniforge3-4.10.3-10/envs/datasci/lib/python3.10/site-packages/torch/autograd/__init__.py:200, in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs)
195 retain_graph = create_graph
197 # The reason we repeat same the comment below is that
198 # some Python versions print out the first line of a multi-line function
199 # calls in the traceback and some print out the last line
--> 200 Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
201 tensors, grad_tensors_, retain_graph, create_graph, inputs,
202 allow_unreachable=True, accumulate_grad=True)
KeyboardInterrupt:
15.5. 課題#
[課題1] このノートではmnistデータセットのクラス分類を行うCNNを実装しました.これを主要なパラメータをCLIのオプションで変更できる形にしたプログラムcnn_mnist.pyを作成してください.
Hint
MLPやw2vの実装を参考にしながら,必要なハイパーパラメータやモデルの保存場所などを変更できるようなCLIのオプション(引数)を用意してください.(多分正解はない)
[課題2] CIFAR-10データセットのクラス分類を行うCNNを実装して,訓練とテストデータによる評価までを行うプログラムcnn_cifar10.pyを作成してください.主要なパラメータをCLIのオプションで変更できるようにすること.また,できるだけテスト正解率が高くなるようにモデルをチューニングして,デフォルトの引数として設定すること.
Hint
テストデータに対する正答率が高くなるようにチューニングするように求められていますが,テストデータは基本的に一番最後にだけ利用します.つまり代用として教師データから任意の割合で切り出したバリデーションデータをテストデータとして利用し,バリデーションデータに対する正答率が高くなるようにチューニングをします.その後,課題を提出する段階になったら本物のテストデータに対する正答率を求めてください.
15.6. 参考文献#
- CBD+90
Y Le Cun, B Boser, J S Denker, R E Howard, W Habbard, L D Jackel, and D Henderson. Handwritten digit recognition with a back-propagation network. In Advances in neural information processing systems 2, pages 396–404. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, June 1990.
- DDS+09
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: a large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–255. June 2009. doi:10.1109/CVPR.2009.5206848.
- Fuk80
K Fukushima. Neocognitron: a self organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern., 36(4):193–202, 1980. doi:10.1007/BF00344251.
- KSH12(1,2)
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst., 2012.
- LBD+89
Y LeCun, B Boser, J S Denker, D Henderson, R E Howard, W Hubbard, and L D Jackel. Backpropagation applied to handwritten zip code recognition. Neural Comput., 1(4):541–551, December 1989. doi:10.1162/neco.1989.1.4.541.
- LBBH98
Y Lecun, L Bottou, Y Bengio, and P Haffner. Gradient-based learning applied to document recognition. Proc. IEEE, 86(11):2278–2324, November 1998. doi:10.1109/5.726791.
- SZ14
missing journal in Simonyan2014-wx
- SLJ+15
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1–9. IEEE, June 2015. doi:10.1109/cvpr.2015.7298594.
- 16
岡谷 貴之. 画像認識のための深層学習の研究動向 : 畳込みニューラルネットワークとその利用法の発展(ニューラルネットワーク研究のフロンティア). 人工知能, 31(2):169–179, 2016. doi:10.11517/jjsai.31.2\_169.