3. k-NN (k-Nearest Neighbors Classifier; k近傍法)#
3.1. k近傍法のアルゴリズム#
3.1.1. イメージによる理解#
これ以降では下の用語を使います。
既にクラスがわかっているデータ(教師データ、訓練データ、training dataと呼ばれるもの)
クラスが未知のデータ、クラスを予測したいデータ
教師データとして与えられるデータは、いくつかの特徴を持っているとします。例えばAさんの身体測定のデータを見てみると、Aさんのデータとして身長、体重の数値が与えられています。これが特徴です。特徴は何次元あってもいいですが、ここでは二次元だと考えます。同じように何かしらの二種類の特徴があるデータがあり、いくつかのデータには、既にクラスが割り当てられている状態だとしましょう。ここで未知のデータがどのクラスに割り当てられるのかを予測するのが クラス分類タスク です。
クラス分類タスクを解くために、ここではk-nnを利用します。k-nnでは単純に、テストデータの近い位置にあるデータを\(k\)個集めて、その中の多数決でテストデータのクラスを決定します。

\(k=1\)の場合を考えてみましょう。これは 最近傍法 や1-NNとも呼ばれます。最近傍点に従って,テストデータは青クラスだとします。

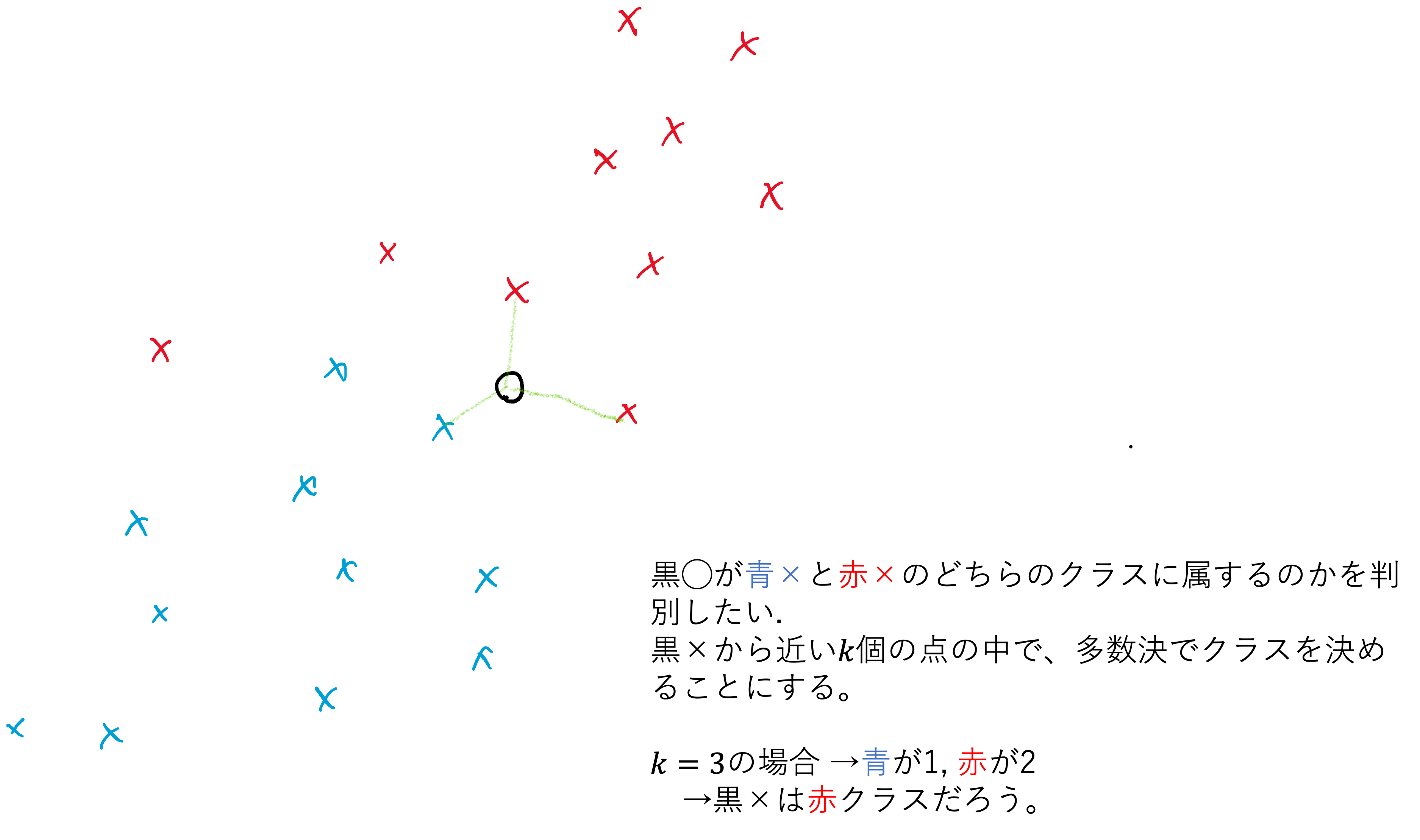
\(k=3\)の場合を考えてみましょう。イメージ画像では近傍の3つのデータは、青1個、赤2個なので、多数決でテストデータを赤クラスに割り当てます。
\(k=5\)の場合を考えてみましょう。イメージ画像では近傍の5つのデータは、青2個、赤3個なので、多数決でテストデータを赤クラスに割り当てます。
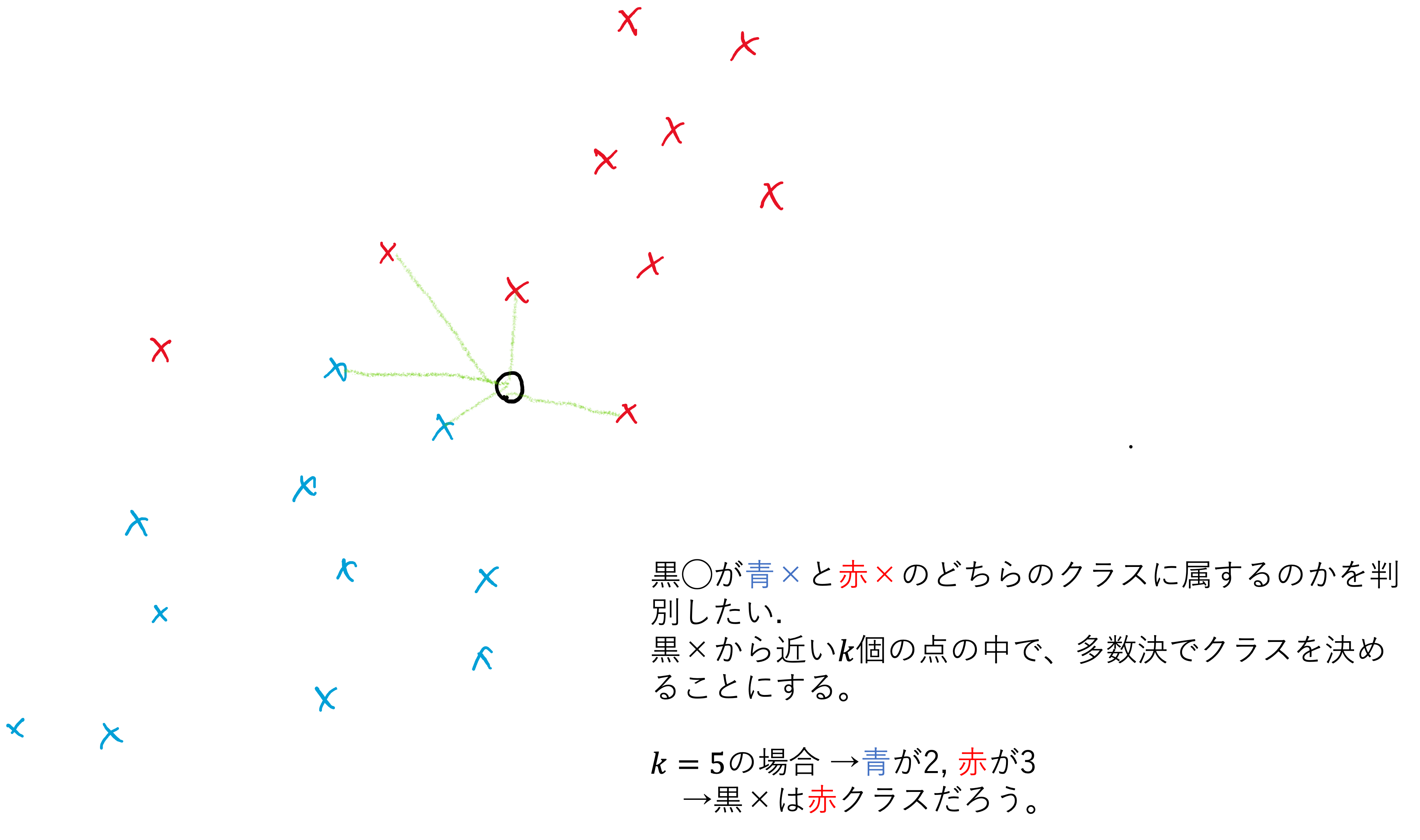
上の三つの例では、kの値を変えることでテストデータの割り当てられるクラスが変わってしまいました。このkの値をk-NNの ハイパーパラメータ(hyper-parameter) と呼びます。ハイパーパラメータは機械学習を行う際に、最終的な結果を大きく左右することがある重要な設定値です。kにどの値を使うかは慎重に考えなければなりません。また、実際にはテストデータが複数ある場合が多いので、この作業をテストデータの数だけ繰り返す必要があることに注意してください。
3.1.2. コードベースの理解#
k-nnにおける処理の流れを簡単にPythonっぽくまとめておきます。初期化ステップ→学習ステップ→予測ステップの順に処理が進んで行きます。
class KNN:
def __init__(self, k:int):
"初期化ステップ"
self.k = k # kの値を決めておく
def fit(self,X:教師データの二次元配列,y:教師データのクラスの入った一次元配列):
"学習ステップ"
self._X = X # 教師データを保存しておく
self._y = y # 教師ラベルを保存しておく
def predict(self, X:テストデータの二次元配列):
"予測ステップ"
pred_y = [] # テストデータの予測ラベルを保存するためのリスト
for x in X:
# xはテストデータから取り出した1つのデータ
1. 教師データをxに近い順にソートする。
2. 近い順にk個の教師データを取り出す。
3. k個の教師データの中で最も多いラベルを見つける。
4. これをxのラベルとする。
pred_y.append(xの予測ラベル)
return pred_y
def score(self,X,y):
pred_y = self.predict(X)
yとpred_yを使って正答率を計算
return 正答率
上に示したコードと日本語が混ざったものは、scikit-learnの実装に似せたメソッドを用意しています。
scikit-learnで実装された機械学習のクラスは以下のように利用します。
__init__でハイパーパラメータを設定
fitで教師データを使ってモデルを訓練
predictでテストデータに対してクラスラベルを予測
k-nnではfitメソッドで教師データセットの保存だけを行っており、これを使って、predictで1~4の流れに沿ってクラスラベルの予測を行っています。
3.2. Scikit-Learnを使った実験#
では実際に、scikit-learnを使ってk-nnを試してみましょう。あやめの花のデータセットであるiris datasetを使ってクラス分類を行います。
# このノートで使うパッケージをimportしておきます。
import numpy as np
import pandas as pd
import plotly.express as px
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
実験のために、まずは疑似乱数のシードを固定しておきます。このSEEDの値を決めておくことで、再度同様の実験を行なっても同じ答えになるはずです。
また、データセットの読み込みも行います。ここではiris datasetを利用するので、これを読み込んでtrain_test_splitで教師データとテストデータを分割しておきます。test_sizeは全体に対するテストデータの割合を示します。この値は0.3としますが、値が大きいほど難しい課題設定になる傾向があります。
SEED = 2023_02_01
rng = np.random.default_rng(SEED)
np.random.seed(SEED)
# デモで使うデータセットを読み込んでおきます。
iris_dataset = load_iris()
# 教師データとテストデータに分割します。
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset.data, iris_dataset.target, # 分割したい配列をここに列挙します。今回はデータとラベルです。
test_size=0.3, # データ全体に対するテストデータの割合を指定します。
#stratify=iris_dataset.target, # クラス毎に偏りが出ないような分割をします。
random_state= SEED, # random_state=None
)
iris datasetではあまり必要性がないですが、StandardScalerで正規化しておきます。データを平均0、標準偏差1のガウス分布(標準正規分布)に埋め込む作業です。これによって特徴毎に値のスケールが違う場合でも差異を吸収することができます。
# データを標準化しておきます。(このセルを実行しなくても構いません)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
モデルの初期化です。KNeighborsClassifierのコンストラクタ(初期化メソッド)では、ここで示した以外にもいくつかのオプションがあります。調べてみると良いでしょう。また、n_jobsは訓練や推論を並列で行うためのオプションです。並列化しないのであれば指定しなくてもいいのですが、指定する場合はn_jobsの値によって答えが変わるような実装になっている場合があることに注意してください。つまりn_jobs=-1の場合、その環境で最も良い値を指定してくれるはずですが、これは環境依存の値なのでSEEDを固定していても値が変わる場合があるのです。
# モデルの初期化
model = KNeighborsClassifier(
n_neighbors=1, # kの値
n_jobs=1, # 並列計算する数、ここでは1にしているが、計算に時間がかかる場合はCPUのコア数を指定するとよい。
)
訓練はscikit-learn準拠モデルではfitメソッドが担います。教師データと教師ラベルを受け取って、学習が終わった自分自身を返します(return self)。もちろんmodel自体のパラメータも更新されています。
knnではX_trainとy_trainを推論のためにinstance変数に代入するだけの処理をしていると考えてください。
# モデルの訓練
model.fit(X_train,y_train)
KNeighborsClassifier(n_jobs=1, n_neighbors=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
KNeighborsClassifier(n_jobs=1, n_neighbors=1)
推論はscikit-learn準拠モデルではpredictメソッドが担います。データのみを受け取って、予測したラベルを返します。ここではテストデータを渡しましたが、訓練データを渡しても同じようにラベルを返します。ただし、通常は汎化誤差を確認したいはずなので、テストデータに対する予測値を見ることが多いと思います。
# 訓練済みモデルを使ったTest dataのクラス予測
model.predict(X_test)
array([1, 0, 0, 2, 1, 2, 0, 1, 0, 2, 2, 2, 1, 2, 2, 0, 0, 0, 0, 1, 0, 1,
1, 2, 2, 1, 2, 2, 2, 1, 1, 2, 0, 2, 2, 1, 1, 0, 2, 2, 2, 1, 0, 0,
0])
KNeighborsClassifierのようなクラス分類のためのクラスであれば、正答率を返すようにscoreメソッドが実装されています。これを使ってtraining data accuracyとtest data accuracyを確認しましょう。
# 正答率の算出
train_acc = model.score(X_train,y_train)
test_acc = model.score(X_test,y_test)
print("教師データの正答率:", train_acc)
print("テストデータの正答率:", test_acc)
教師データの正答率: 1.0
テストデータの正答率: 0.9111111111111111
iris datasetは非常にクラス分類しやすいデータです。正答率が高めになっているのもそのためでしょう。
テストデータの正答率は1に近いほど良いので、kがどの値の時に良い正答率が得られるのかを確認してみましょう。
def get_fold(X_train,y_train,n_fold=5, seed=None):
index = np.arange(len(y_train))
if seed is not None:
np.random.seed(seed)
np.random.shuffle(index)
folds = np.array_split(index,n_fold)
for ix in range(n_fold):
fold = folds[ix]
other = np.hstack([folds[j] for j in range(n_fold) if j != ix])
yield {
"X_val":X_train[fold],
"y_val":y_train[fold],
"X_train":X_train[other],
"y_train":y_train[other],
}
def grid_search(X_train, y_train, test_size=0.3, k=50, n_fold=4, seed=None):
seed = seed if seed is not None else np.random.randint(2**20)
val_acc_list = []
for _k in range(1,k+1):
tmp = []
for data in get_fold(X_train,y_train,n_fold,seed):
knn = KNeighborsClassifier(n_neighbors=_k).fit(data["X_train"],data["y_train"])
val_acc = knn.score(data["X_val"], data["y_val"])
tmp.append(val_acc)
val_acc_list.append(np.mean(tmp))
df = pd.DataFrame()
df["k"] = list(range(1,k+1))
df["acc"] = val_acc_list
"""
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(df["k"], df["acc"])
ax.set_xlabel('$k$ (n_components)')
ax.set_ylabel('Accuracy')
ax.set_title("Elbow plot")
"""
return df
result_df = grid_search(X_train,y_train,seed=SEED)
fig = px.line(
result_df,
x="k", y="acc",
height=400, width=400,
title="kとacc(正答率)との関係")
fig.show()
kとaccの関係を示す上のプロットから、適切なkの値を見ることができます。
best_k = int(result_df.iloc[result_df["acc"].argmax()]["k"])
result_df.iloc[result_df["acc"].argmax()]
k 7.000000
acc 0.981125
Name: 6, dtype: float64
最後に、適切なkの値を使ってtest accuracyを求めておきます。
knn = KNeighborsClassifier(n_neighbors=best_k).fit(X_train,y_train)
knn.score(X_test,y_test)
0.9555555555555556