
NOTE: この資料について
この資料では、§2 に GA の一般論(用語・流れ・チェックリスト)を置き、手書き数字認識を サポートベクタマシン(SVM) で行うときに、どの画素(特徴)を使うかを binary 符号化(ビット列) で探索する流れをまとめる。§5 で テスト精度 と %%timeit による速度 をベースラインと比較する。
各遺伝子は「その特徴を使うか(1)/使わないか(0)」に対応する 組合せ最適化 問題として定式化できる。
GA の用語の骨格は 遺伝的アルゴリズム(立命館大学 情報理工学部 資料) に概ね沿っている。
0. 到達目標¶
この回の終了時に、次を説明し、コードの対応関係まで辿れることを目指す。
§2 の GA 用語(個体・適応度・選択・交叉・突然変異・世代交代)と、世代の 流れ を説明できる。
特徴選択を 長さ のビット列(binary chromosome) で表し、表現型として部分特徴ベクトルを取り出せる。
適応度(fitness) を、選択した特徴だけで学習した SVM の 交差検証(cross-validation)正解率 で定義できる。
binary GA における 一様交叉 と ビット反転突然変異 の役割を述べられる。
全特徴 と GA 選択特徴 で、テスト正解率および 学習・推論の所要時間 を比較できる。
1. 問題設定:SVM と特徴選択¶
1.1 データ¶
sklearn.datasets.load_digits は、 画素の手書き数字(クラス数 10)を、 次元のベクトルとして与える。各次元は 画素の明るさ(特徴) に対応する。
1.2 分類器¶
線形 SVM(sklearn.svm.LinearSVC)を用いる。多クラスではデフォルトで OvR(one-vs-rest) が用いられる。SVC(kernel="linear") より小規模データでは高速なことが多い。
1.3 binary 染色体¶
長さ のベクトル で、 とする。 のときだけ 番目の特徴を採用する。
とし、学習・評価に使う行列は列部分集合 だけを取り出したものとする。
全て 0 の個体は特徴が空で分類できないため、適応度は 0(または極小)とするか、少なくとも 1 ビットは 1 という制約を課す。
1.4 適応度(最大化)¶
学習データ上で 分割交差検証 の平均正解率を とする。
(発展)特徴数ペナルティを入れるなら なども用いられる。
2. 遺伝的アルゴリズム(GA)の概要¶
GA の 一般論(用語・世代の流れ・実装チェックリスト) は本節でまとめる。
順列符号化(TSP など) で異なる点の補足は 第3回:遺伝的アルゴリズム(GA)で巡回セールスマン問題(TSP)を解く を参照する。
2.0 用語集(Glossary)¶
定義の骨格は「遺伝的アルゴリズム」および 立命館大学の資料 に沿う。
| 用語 | 英語など | 意味(要約) |
|---|---|---|
| 遺伝子型 | genotype;GTYPE | 交叉・突然変異が直接操作する内部表現(本ノートではビット列)。 |
| 表現型 | phenotype;PTYPE | GTYPE が 問題文脈でどう解釈されるか(ここでは選んだ特徴の部分集合)。 |
| 符号化 | encoding | 解を GTYPE に対応づける設計(binary 特徴選択では長さ の 0/1 ベクトル)。 |
| 個体 | individual | 1 つの解候補 とその適応度。 |
| 個体集団 | population | 世代 の集団を と書く。 |
| 世代 | generation | 集団を 1 回更新するステップの添字 。 |
| 適応度 | fitness | 個体の良さ。最大化が基本。最小化目的は変換してから選択に用いる。 |
| 選択 | selection | 適応度に応じて 親 を選ぶ。 |
| トーナメント選択 | tournament selection | 無作為に 体取り、その中の最良を親にする(本ノートの実装)。 |
| エリート | elitism | 最良個体を次世代に残す戦略。 |
| 交叉 | crossover | 親の GTYPE を組み替えて子を作る。 |
| 突然変異 | mutation | GTYPE を確率的に変える。 |
| 終了条件 | termination | 世代数上限、時間、改善停滞など。 |
個体は 染色体(chromosome) で符号化され、選択 → 交叉 → 突然変異 を繰り返して を更新する。
2.1 全体の流れ¶
: 世代 の集団
終了条件(例: 最大世代数 )まで、評価 → 選択 → 交叉 → 突然変異 → 世代交代 を繰り返す。
終了後、最も適応度が高い個体を 近似解 として出力する。
ルーレット選択(適応度比例)を想定した流れを示す(本ノートのコードは トーナメント選択 だが、ループ構造は同じである)。
2.2 実装チェックリスト(binary 特徴選択の場合)¶
初期化:長さ のビット列を 個生成し とする。
評価:マスクで列を抜き出した学習データで SVM を CV し、平均正解率を とする。
選択:トーナメント(またはルーレット等)で親を選ぶ。
交叉:一様交叉(各位置で親のどちらかから継承)。
突然変異:ビット反転。
世代交代:子と エリート から を作る。
終了まで 2〜6 を繰り返す。
NOTE: GA は最適解を保証しない
得られるのは制限時間・世代数の中での 近似解 である。最良値の推移 や 乱数シードを変えた試行 を確認することが重要である。
3. binary 符号化における遺伝的操作(本ノートで用いる具体)¶
| 操作 | 内容(本ノート) |
|---|---|
| 選択 | トーナメント選択(実装が単純で安定しやすい) |
| 交叉 | 一様交叉:各遺伝子で親をどちらかから選ぶ |
| 突然変異 | ビット反転:各ビットを確率 で反転 |
| 世代交代 | 子生成後、エリートを上位から次世代に複製 |
TSP のような 順列制約 はないため、ビット列向けの交叉・突然変異をそのまま用いられる。
from __future__ import annotations
import time
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.metrics import accuracy_score
from sklearn.model_selection import StratifiedKFold, cross_val_score, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
RANDOM_STATE = 42
rng = np.random.default_rng(RANDOM_STATE)
digits = load_digits()
X, y = digits.data, digits.target
n_features = X.shape[1]
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.25,
stratify=y,
random_state=RANDOM_STATE,
)
print(f"サンプル数: train={X_train.shape[0]}, test={X_test.shape[0]}")
print(f"特徴次元 d={n_features}(8x8 画素)")サンプル数: train=1347, test=450
特徴次元 d=64(8x8 画素)
ベースライン:全特徴を用いた SVM¶
特徴量のスケールを揃えるため 標準化(StandardScaler) をパイプラインに入れる。
def make_svm_pipeline() -> Pipeline:
"""標準化後に線形 SVM(LinearSVC)を適用するパイプラインを返す。"""
return Pipeline(
[
("scaler", StandardScaler()),
(
"svc",
LinearSVC(
dual="auto",
C=1.0,
max_iter=10_000,
random_state=RANDOM_STATE,
),
),
]
)
baseline_clf = make_svm_pipeline()
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=RANDOM_STATE)
baseline_cv = cross_val_score(baseline_clf, X_train, y_train, cv=cv, n_jobs=-1)
baseline_clf.fit(X_train, y_train)
baseline_test = accuracy_score(y_test, baseline_clf.predict(X_test))
print(f"全特徴・CV 平均正解率: {baseline_cv.mean():.4f} (+/- {baseline_cv.std():.4f})")
print(f"全特徴・テスト正解率: {baseline_test:.4f}")全特徴・CV 平均正解率: 0.9495 (+/- 0.0073)
全特徴・テスト正解率: 0.9511
4. 実装:binary GA(特徴マスクの探索)¶
以下の関数は 学習データ X_train, y_train 上の CV スコア を適応度とする。汎化性能の最終確認は 保持したテスト集合 で行う。
def mask_features(X: np.ndarray, mask: np.ndarray) -> np.ndarray:
"""bool または 0/1 のマスクで列を選択する。"""
m = mask.astype(bool)
return X[:, m]
def fitness_svm_cv(
mask: np.ndarray,
X_tr: np.ndarray,
y_tr: np.ndarray,
cv_splits: StratifiedKFold,
min_features: int = 1,
) -> float:
"""マスクに対応する部分特徴で SVM を学習し、CV 平均正解率を返す。
選択特徴数が ``min_features`` 未満のときは 0.0 を返す。
"""
if int(mask.sum()) < min_features:
return 0.0
Xm = mask_features(X_tr, mask)
clf = make_svm_pipeline()
scores = cross_val_score(clf, Xm, y_tr, cv=cv_splits, n_jobs=-1)
return float(scores.mean())
def random_binary_chromosome(n_genes: int, rng: np.random.Generator) -> np.ndarray:
"""一様乱数で 0/1 染色体を生成する。"""
return rng.integers(0, 2, size=n_genes, dtype=np.int8)
def initial_population_binary(
pop_size: int, n_genes: int, rng: np.random.Generator
) -> np.ndarray:
"""初期集団(各行が1個体のビット列)。"""
rows = [random_binary_chromosome(n_genes, rng) for _ in range(pop_size)]
return np.stack(rows, axis=0)
def tournament_parent_index(
fitness: np.ndarray, k: int, rng: np.random.Generator
) -> int:
"""トーナメント選択で親1体の添字を返す。"""
n = fitness.shape[0]
k = min(k, n)
contenders = rng.choice(n, size=k, replace=False)
return int(contenders[np.argmax(fitness[contenders])])
def take_elites(
population: np.ndarray,
fitness: np.ndarray,
elite_count: int,
) -> np.ndarray:
"""適応度上位 elite_count 個体をコピーして返す。"""
order = np.argsort(-fitness)
return population[order[:elite_count]].copy()
def uniform_crossover_one_child(
p1: np.ndarray, p2: np.ndarray, rng: np.random.Generator
) -> np.ndarray:
"""一様交叉で子1体を生成する。"""
mask = rng.random(size=p1.shape[0]) < 0.5
child = np.where(mask, p1, p2)
return child.astype(np.int8)
def maybe_crossover(
p1: np.ndarray,
p2: np.ndarray,
crossover_prob: float,
rng: np.random.Generator,
) -> tuple[np.ndarray, np.ndarray]:
"""交叉確率に従い一様交叉するか、親のコピーを返す。"""
if rng.random() > crossover_prob:
return p1.copy(), p2.copy()
c1 = uniform_crossover_one_child(p1, p2, rng)
c2 = uniform_crossover_one_child(p2, p1, rng)
return c1, c2
def bit_flip_mutation(
chromosome: np.ndarray, mutation_prob: float, rng: np.random.Generator
) -> np.ndarray:
"""各ビットを独立に確率 mutation_prob で反転する。"""
out = chromosome.copy()
flip = rng.random(size=out.shape[0]) < mutation_prob
out[flip] = 1 - out[flip]
return out.astype(np.int8)
def evaluate_population(
population: np.ndarray,
X_tr: np.ndarray,
y_tr: np.ndarray,
cv_splits: StratifiedKFold,
) -> np.ndarray:
"""集団の各行に対する適応度ベクトルを返す。"""
fits = np.empty(population.shape[0], dtype=np.float64)
for i in range(population.shape[0]):
fits[i] = fitness_svm_cv(population[i], X_tr, y_tr, cv_splits)
return fits
def next_generation_from_offspring(
offspring: np.ndarray,
elites: np.ndarray,
pop_size: int,
) -> np.ndarray:
"""エリートと子を連結し、先頭 pop_size 行を次世代とする。"""
merged = np.vstack([elites, offspring])
return merged[:pop_size].copy()
def ga_binary_one_generation(
population: np.ndarray,
X_tr: np.ndarray,
y_tr: np.ndarray,
cv_splits: StratifiedKFold,
rng: np.random.Generator,
pop_size: int,
crossover_prob: float,
mutation_prob: float,
elite_count: int,
tournament_k: int,
) -> tuple[np.ndarray, float, int]:
"""1世代進める。戻り値は (次世代, 最良適応度, 最良個体の選択特徴数)。"""
fitness = evaluate_population(population, X_tr, y_tr, cv_splits)
best_idx = int(np.argmax(fitness))
best_fit = float(fitness[best_idx])
best_k = int(population[best_idx].sum())
elites = take_elites(population, fitness, elite_count)
rows: list[np.ndarray] = []
need = max(0, pop_size - elite_count)
while len(rows) < need:
i = tournament_parent_index(fitness, tournament_k, rng)
j = tournament_parent_index(fitness, tournament_k, rng)
c1, c2 = maybe_crossover(
population[i], population[j], crossover_prob, rng
)
rows.append(bit_flip_mutation(c1, mutation_prob, rng))
if len(rows) < need:
rows.append(bit_flip_mutation(c2, mutation_prob, rng))
offspring = np.stack(rows, axis=0)
new_pop = next_generation_from_offspring(offspring, elites, pop_size)
return new_pop, best_fit, best_k
def run_ga_binary_feature_selection(
population: np.ndarray,
X_tr: np.ndarray,
y_tr: np.ndarray,
cv_splits: StratifiedKFold,
generations: int,
rng: np.random.Generator,
pop_size: int,
crossover_prob: float,
mutation_prob: float,
elite_count: int,
tournament_k: int,
) -> tuple[np.ndarray, np.ndarray, np.ndarray]:
"""GA を実行し、(最終集団, 各世代最良CVスコア, 各世代最良の特徴数) を返す。"""
pop = population.copy()
trace_fit = np.empty(generations, dtype=np.float64)
trace_k = np.empty(generations, dtype=np.int64)
for t in range(generations):
pop, bf, bk = ga_binary_one_generation(
pop,
X_tr,
y_tr,
cv_splits,
rng,
pop_size,
crossover_prob,
mutation_prob,
elite_count,
tournament_k,
)
trace_fit[t] = bf
trace_k[t] = bk
return pop, trace_fit, trace_k実行例:パラメータはデータ規模に合わせて調整する¶
CV は評価のたびに呼ぶため、世代数・集団サイズ を大きくしすぎると時間がかかる。
POP_SIZE = 24
GENERATIONS = 40
CROSSOVER_PROB = 0.9
MUTATION_PROB = 0.05
ELITE_COUNT = 2
TOURNAMENT_K = 3
pop0 = initial_population_binary(POP_SIZE, n_features, rng)
_t_ga0 = time.perf_counter()
pop_final, trace_fit, trace_k = run_ga_binary_feature_selection(
pop0,
X_train,
y_train,
cv,
GENERATIONS,
rng,
POP_SIZE,
CROSSOVER_PROB,
MUTATION_PROB,
ELITE_COUNT,
TOURNAMENT_K,
)
ga_search_seconds = time.perf_counter() - _t_ga0
final_fitness = evaluate_population(pop_final, X_train, y_train, cv)
best_row = int(np.argmax(final_fitness))
best_mask = pop_final[best_row].astype(bool)
best_cv = float(final_fitness[best_row])
n_selected = int(best_mask.sum())
clf_ga = make_svm_pipeline()
clf_ga.fit(mask_features(X_train, best_mask), y_train)
test_acc_ga = accuracy_score(
y_test, clf_ga.predict(mask_features(X_test, best_mask))
)
print(f"GA 終了時・最良 CV 平均正解率: {best_cv:.4f}")
print(f"選択特徴数: {n_selected} / {n_features}")
print(f"テスト正解率(GA 選択特徴): {test_acc_ga:.4f}")
print(f"(参考)全特徴テスト正解率: {baseline_test:.4f}")
print(f"GA 探索(特徴選択)の wall time: {ga_search_seconds:.2f} s")GA 終了時・最良 CV 平均正解率: 0.9621
選択特徴数: 46 / 64
テスト正解率(GA 選択特徴): 0.9533
(参考)全特徴テスト正解率: 0.9511
GA 探索(特徴選択)の wall time: 49.65 s
fig, ax = plt.subplots(1, 2, figsize=(10, 4))
ax[0].plot(trace_fit, marker="o", markersize=2)
ax[0].set_xlabel("generation")
ax[0].set_ylabel("best CV accuracy (per generation)")
ax[0].set_title("Best fitness trace")
ax[0].grid(True, alpha=0.3)
ax[1].plot(trace_k, marker="o", markersize=2, color="tab:orange")
ax[1].set_xlabel("generation")
ax[1].set_ylabel("# of selected features (best in gen)")
ax[1].set_title("Feature count of best individual")
ax[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()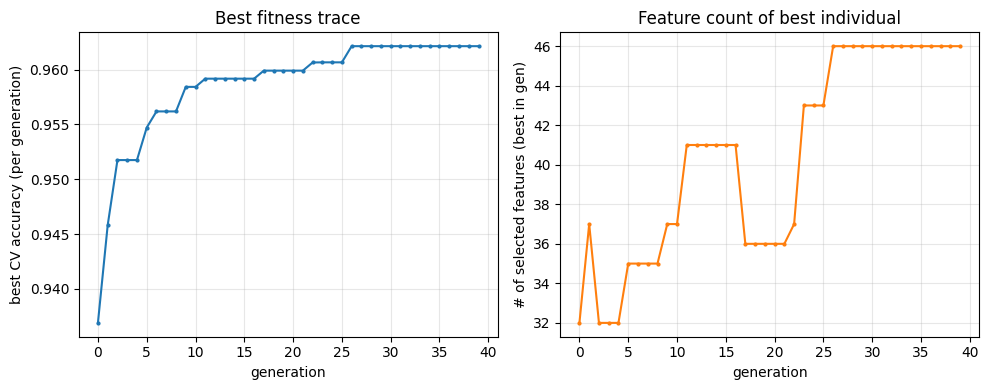
選択マスクの可視化( に戻す)¶
どの画素位置が選ばれたかを ヒートマップ で表示する。
mask_img = best_mask.reshape(8, 8).astype(float)
plt.figure(figsize=(4, 4))
plt.imshow(mask_img, cmap="gray_r", vmin=0, vmax=1)
plt.title("Selected pixels (1=white)")
plt.colorbar(shrink=0.7)
plt.axis("off")
plt.tight_layout()
plt.show()
5. 動作確認:テスト精度と %%timeit による速度¶
正解率は上のセルで既に計算した baseline_test(全特徴)と test_acc_ga(GA が選んだマスク)を並べて比較する。
速度は用途が異なる次の3つに分けるとよい。
GA 探索そのもの:
fitness計算で CV を多数回呼ぶため、壁時計時間はga_search_seconds(上の GA セルで計測)が支配的である。特徴集合が決まったあとの SVM:学習(
fit)と推論(predict)を毎回まとめて測る(%%timeitのセル)。特徴数が少ないと速くなる場合がある。学習済みモデルに対する推論のみ:別セルで一度だけ
fitし、その後の%%timeitはpredictだけ を測る。
%%timeit は IPython / Jupyter のマジックである。先頭行に %%timeit を書くセルとして実行する。
print("=== テストデータに対する正解率(accuracy)===")
print(f" 全特徴(ベースライン, d={n_features}) : {baseline_test:.6f}")
print(f" GA 選択特徴(選択数 {n_selected}) : {test_acc_ga:.6f}")
print()
print("=== 所要時間の見方 ===")
print(f" GA による特徴選択(探索全体・CV 含む): {ga_search_seconds:.2f} s")
print(" 下のセル: `%%timeit` により **学習+推論** または **推論のみ** の1回あたり時間を測る。")=== テストデータに対する正解率(accuracy)===
全特徴(ベースライン, d=64) : 0.951111
GA 選択特徴(選択数 46) : 0.953333
=== 所要時間の見方 ===
GA による特徴選択(探索全体・CV 含む): 49.65 s
下のセル: `%%timeit` により **学習+推論** または **推論のみ** の1回あたり時間を測る。
# 推論のみを %%timeit するため、学習済みモデルを1回だけ作る(このセルは1回実行すること)
_clf_all_fit = make_svm_pipeline()
_clf_all_fit.fit(X_train, y_train)
_clf_sub_fit = make_svm_pipeline()
_clf_sub_fit.fit(mask_features(X_train, best_mask), y_train)
X_test_sub = mask_features(X_test, best_mask)学習と推論を毎回やり直す(fit + predict)¶
%%timeit の各反復で 新しいパイプライン を作り、学習データで fit したあとテストデータで predict する。特徴次元が小さい GA 側が、1回あたり速くなることが多い(環境依存)。
%%timeit -n 10 -r 3
make_svm_pipeline().fit(X_train, y_train).predict(X_test)194 ms ± 6.43 ms per loop (mean ± std. dev. of 3 runs, 10 loops each)
%%timeit -n 10 -r 3
make_svm_pipeline().fit(mask_features(X_train, best_mask), y_train).predict(
mask_features(X_test, best_mask)
)59.5 ms ± 44.1 μs per loop (mean ± std. dev. of 3 runs, 10 loops each)
推論のみ(predict)¶
直前のセルで 一度だけ fit した _clf_all_fit と _clf_sub_fit を用い、テスト集合への predict だけ の所要時間を比較する。
%%timeit -n 40 -r 4
_clf_all_fit.predict(X_test)127 μs ± 12 μs per loop (mean ± std. dev. of 4 runs, 40 loops each)
%%timeit -n 40 -r 4
_clf_sub_fit.predict(X_test_sub)112 μs ± 16.2 μs per loop (mean ± std. dev. of 4 runs, 40 loops each)
6. パラメータと注意点¶
個体数が小さい と多様性が不足し、局所的なマスクに張り付きやすい。
突然変異率が大きすぎる と良いビット列が壊れやすい。小さすぎる と探索が停滞する。
適応度を 学習データの CV のみにすると 過学習した特徴集合 を選ぶ可能性がある。本ノートでは ホールドアウトテスト で最終確認している。
GA は 大域最適を保証しない。複数シードで試し、最良値の推移 を見ることが重要である。
7. 演習の例¶
ペナルティ付き適応度 を実装し、特徴数と正解率のトレードオフを調べる。
MUTATION_PROBまたはPOP_SIZEを変え、最終 CV およびテスト正解率の変化を比較する。(発展)
RFEやSelectKBestなどの 貪欲・フィルタ法 と、GA で得たマスクを定性的に比較する。
9. 確認問題¶
本ノートの染色体の長さはなぜ 64 か。
一様交叉を、順列染色体(TSP)にそのまま適用すると何が起こりうるか。
適応度に交差検証を用いる理由を、過学習の観点から述べよ。
全ビット 0 の個体に低い適応度を与える必要があるか。
テスト正解率がベースラインより下がる場合、どのような要因が考えられるか。